个人笔记
SongPinru 的小仓库
大数据平台管理方案探索
宋品如
背景
目前市面上主要使用的Hadoop版本:
- Apache(最原始的版本,所有发行版均基于这个版本进行改进)
- Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称CDH)
- Hortonworks版本(Hortonworks Data Platform,简称HDP)
大多数公司都不会选择Apache版本,因为安装复杂,运维困难,更严重的是hadoop生态的兼容性无法保证,使用Apache版本需要付出极大的资源。
因此,大多数公司都是在CDH和HDP中选择,其中CDH闭源免费(2021年之前),HDP开源免费(2021年之前),自从Cloudera收购Hortonworks之后,CDH和HDP合并为CDP,正式走向了闭源收费的路,hadoop生态的免费时代已经结束。
从2021年1月31日开始,所有Cloudera软件都需要有效的订阅,并且只能通过付费墙进行访问。这包括以下产品的所有先前版本:包含Apache Hadoop的 Cloudera 发行版 (CDH),Hortonworks Data Platform (HDP),Data Flow (HDF / CDF) 和Cloudera Data Science Workbench (CDSW) 。

PS:CDP目前的收费策略是 ==$10000/台、年==

图中的variable意思是以每台机器16 core(满足1core=1CCU)、128G RAM、48T硬盘为标准,配置低的会便宜,配置高的会加价
我们现有的hadoop集群是基于CDH的,在目前状况下,我们的集群无法升级,操作系统和hadoop生态的版本都被锁死,比较幸运的是我们使用的CDH6.3.2+Ubuntu18.04是最后一个免费版支持的最高版本,给我们留下的窗口期还算比较长,暂时对我们的影响不大。
CDH收费后,我们的集群可选择方案其实不多:
-
CDH企业版(CDP)
- 可靠完善,但是太贵
-
Apache 发行版
- 运维负担大,部署麻烦
- ansible / puppet + Zabbix
- 需要专业的大数据运维团队
-
其他厂商提供的大数据平台(USDP,华为fusioninsight)
- USDP和华为都不开源
- 华为没有免费版(而且华为fusioninsight现已停止开发)
- 云服务商出于商业利益,免费不可持续
-
自研方案
- 资源投入大,周期长
-
Ambari 定制
- 学习成本高
- 相对可靠,Amabri相对比较成熟,经受了长时间检验
- 可控性强,完全开源,可以自己维护一个分支
探索
Ambari介绍
Ambari 是 Apache Software Foundation 的一个顶级开源项目,主要功能:
- 部署:自动化部署 Hadoop 软件,能够自动处理服务、组件之间的依赖(比如 HBase 依赖 HDFS,DataNode 启动的时候,需要 NameNode 先启动等)。
- 管理:Hadoop 服务组件的启动、停止、重启,配置文件的多版本管理。
- 监控:Hadoop 服务的当前状态(组件节点的存活情况、YARN 任务执行情况等),当前主机的状态(内存、硬盘、CPU、网络等),而且可以自定义报警事件。
Ambari是一个管理hadoop集群的工具,他不提供具体的hadoop及其生态的安装包,他只提供出了安装,管理,监控等操作的接口,如果想要完整使用Ambari管理hadoop集群,还需要提供一个==Stack+Repository== 。
Repository 实际上是包管理器的软件仓库,其实就是一堆可以安装的软件包
Stack是一堆配置+脚本的集合,用来定义Ambari怎么安装软件包,以及怎么使用安装好的软件的
调用关系:Ambari -> Stack ->Respository
使用最广泛的Stack就是Hortonworks提供的HDP,但是由于Cloudera的收购,HDP现在已经闭源收费,作为替代,我们需要自己实现一个Stack。
HDP是一个stack,同时Hortonworks提供了HDP使用的Repository(准确来说他俩合起来才是HDP)
Ambari主要概念
Ambari-server
Amabri的Server节点,只有一个节点,整个集群的数据由Ambari-Server存储在数据库中
Host
运行ambari-agent的机器,集群的一个节点,在集群的节点上可以启用一些角色(如NameNode,DataNode等),进而对角色的状态进行控制、监控
Component
组件,运行于Host之上,一个角色就是一个组件的具体实例,比如:DataNode可以有多个,整体DataNode就是一个Component,主机上运行的一个DataNode进程就是一个角色
Service
服务,包含多个Component,即一个完整的框架,比如HDFS就分为NameNode,DataNode,JournalNode,FailoverController,gateway等,这些组件Component组成了一个Service
Stack
堆栈,一堆service的集合,实际生产中使用的框架很多,他们之间又经常有依赖关系,因此把他们整合到一起,称为一个Stack,可以理解为大数据平台的一个发行版,比如HDP就是HortonWork公司的大数据平台发行版,HDP就是一个Stack,我们的主要工作内容就是实现一个HDP的替代品,暂命名为IDP
Mpack
Amabri的路线图中计划将Ambari和Stack解耦,这样Stack的更改就不需要重新编译打包Ambari,因此提出了Mpack,Mpack就是一个tar包,里面包含了stacks和mpack.json(对stack的定义)
Mpack就是对stacks的再一层封装,实现与Ambari的解耦
定制stack
上面说了,我们需要自定义一个stack才能使用,为了验证Amabri的可用性,我们实现了一个最小的stack,暂命名IDP
这个stack只包含一个==Service==:HDFS
HDFS里面只有两个==Component==:NameNode、DataNode
为了减少复杂度,我们没有专门准备一个Repository(按照Ambari的要求,这里需要封装成deb包),而是在脚本里直接去Apache下载了最新版的hadoop,然后解压到/usr/idp/lib/hadoop目录
然后将这个stack打包成了一个Mpack,这样我们每次修改stack只需要重新安装mpack就可以了
AMbari的路线图上,stack和Amabri是要完全解耦的,但是这个工作还没有完全结束,他就被收购了,因此我们需要对Amabri-server的代码做一定改动,去除HDP相关的部分,才能正常使用我们定义的stack
这里演示一下安装整体安装流程,理解起来会清晰一些
Ambari架构
Ambari是个典型的前后端分离的设计,主要由三部分组成:ambari-agent、ambari-server、ambari-web。
前端通过http、==websocket==(内部是stomp协议)和server通信。
server和agent通过==stomp==(也套了层websocket)通信。
架构图
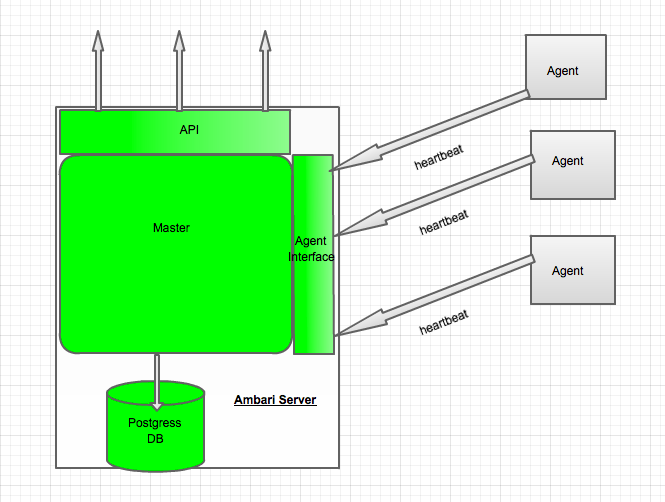
Ambari采用的是Server/Client的模式,后端分为:ambari-server、ambari-agent。
Amabri-server
Amabri-server是一个状态机,维护以下状态到外部数据库:
- Live Cluster State:集群现有状态,各个节点汇报上来的状态信息会更改该状态;
- Desired State:用户希望该节点所处状态,是用户在页面进行了一系列的操作,需要更改某些服务的状态,这些状态还没有在节点上产生作用;
- Action State:操作状态,是状态改变时的请求状态,也可以看作是一种中间状态,这种状态可以辅助LiveCluster State向Desired State状态转变。
同时,Ambari-server也是一个WebServer,提供给ambari-web和ambari-agent访问
Ambari-agent
Ambari-agent是一个无状态的,其功能分两部分:
- 采集所在节点的信息并且汇总发送心跳发送汇报给ambari-server。
- 处理ambari-server的执行请求。
通信流程
websocket
websocket是HTML5提出一种全双工通信协议,基于tcp,使用了http来进行握手,浏览器可以使用websocket来进行双向通信。简单的理解就是浏览器可以使用的tcp。
这里需要讲一下为什么需要websocket,http有一个缺陷:通信只能由客户端发起。但是如果我们集群中有一个服务或者节点挂了,我们需要及时的知道,发出告警并做出重起等操作,我们如果用http,通常做法是前端定时请求后端,以求能及时感知。这种做法低效并且浪费资源,使用websocket就可以实现服务端及时通知浏览器端,从而快速定位解决问题。
stomp
我们以简单的两个实例来了解Amabri的通信流程
NameNode的启停
从web-ui上点击NameNode的restart
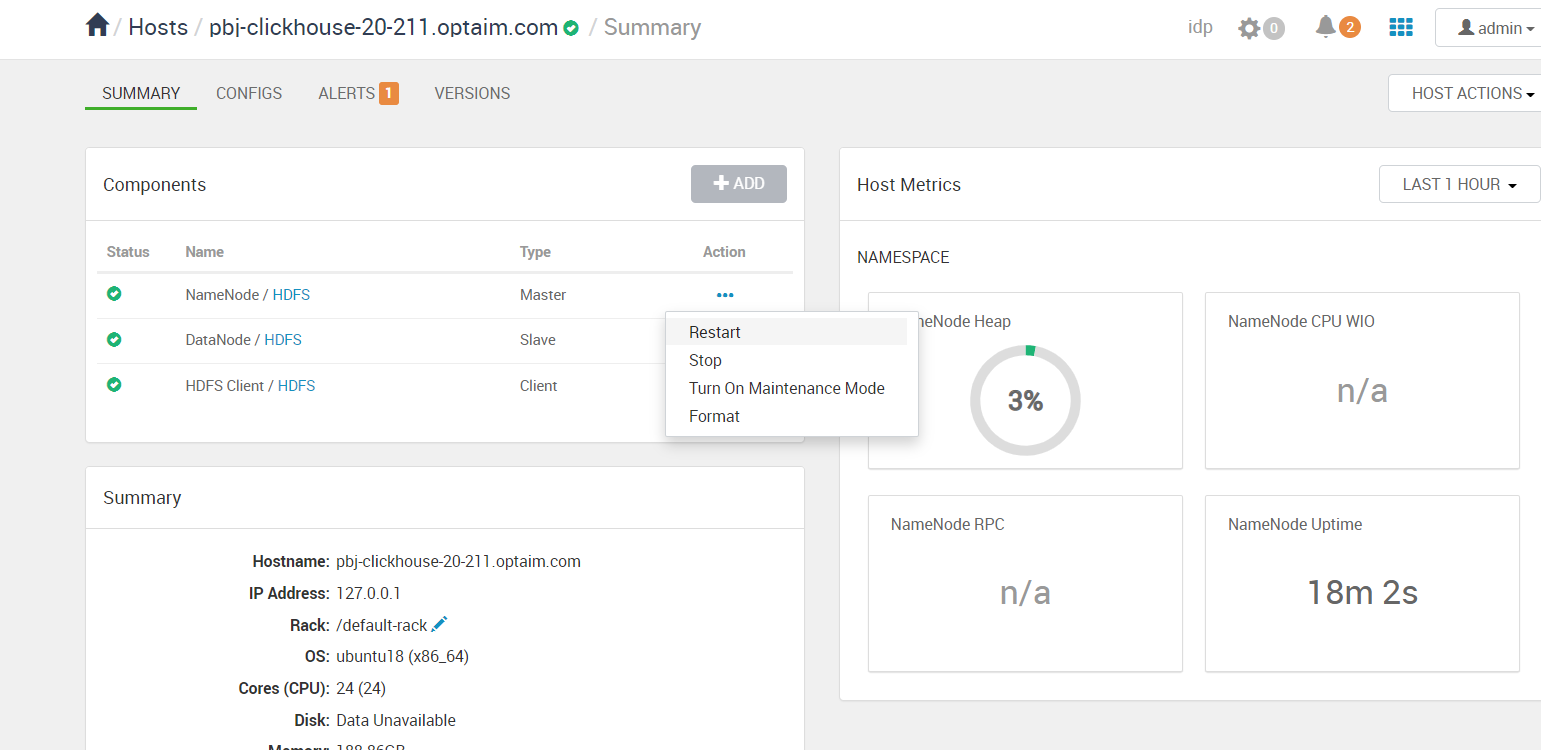
或者使用swagger提供的接口测试(postman等也可以,但是需要设置token)

上面的操作实际上就是向Ambari-server发起了一次http请求,如下:
POST /api/v1/clusters/idp/requests HTTP/1.1
Host: 10.11.20.211:8080
Connection: keep-alive
Content-Length: 311
Accept: application/json, text/javascript, */*; q=0.01
X-Requested-With: XMLHttpRequest
X-Requested-By: X-Requested-By
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.41
Content-Type: text/plain
Origin: http://10.11.20.211:8080
Referer: http://10.11.20.211:8080/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: AMBARISESSIONID=node0sv5cmt5qde8slrausql4ugs3.node0
{
"RequestInfo": {
"operation_level": {
"level": "HOST_COMPONENT",
"cluster_name": "idp",
"service_name": "HDFS",
"hostcomponent_name": "NAMENODE"
},
"command": "STOP",
"context": "Stop NameNode"
},
"Body": {
"Requests": {
"cluster_name": "idp",
"resource_filters": [
{
"service_name": "HDFS",
"component_name": "NAMENODE",
"hosts": "pbj-clickhouse-20-211.optaim.com"
}
],
"exclusive": false
}
}
}
经过server的处理,这个请求会通过stomp协议发送到agent上
MESSAGE
subscription:sub
messageId:48
message-id:68fa4a8d-bb8a-cc1e-22dd-e322f8760776-40249
destination:/user/commands
content-type:application/json;charset=UTF-8
content-length:862
{
"clusters": {
"2": {
"commands": [
{
"roleCommand": "STOP",
"repositoryFile": {
"resolved": false,
"repoVersion": "0.1",
"repositories": [
{
"mirrorsList": null,
"tags": [],
"ambariManaged": true,
"baseUrl": "http://repos.bigtop.apache.org/releases/1.5.0/ubuntu/18.04/$(ARCH)",
"repoName": "IDP",
"components": null,
"distribution": null,
"repoId": "IDP-0.1-repo-1",
"applicableServices": []
}
],
"feature": {
"preInstalled": false,
"scoped": true
},
"stackName": "IDP",
"repoVersionId": 1,
"repoFileName": "ambari-idp-1"
},
"clusterId": "2",
"commandType": "EXECUTION_COMMAND",
"clusterName": "idp",
"serviceName": "HDFS",
"role": "NAMENODE",
"requestId": 60,
"taskId": 96,
"commandParams": {
"script": "scripts/namenode.py",
"hooks_folder": "stack-hooks",
"max_duration_for_retries": "0",
"command_retry_enabled": "false",
"command_timeout": "1800",
"script_type": "PYTHON"
},
"commandId": "60-0"
}
]
}
},
"requiredConfigTimestamp": 1638788225444
}
agent接受到这条消息后,最终会执行我们定义的脚本中的stop方法
namenode挂了向上反馈
首先,我们的脚本里需要实现get_pid_files这个方法,来告诉ambari我们启动的进程的pid是多少
def get_pid_files(self):
return ["/usr/idp/etc/hadoop/pids/hdfs/hadoop-hdfs-datanode.pid"]
ambari会监控这个pid,如果这个进程挂了,就会通知server
SEND
destination:/reports/component_status
content-type:application/json;charset=UTF-8
content-length:232
{
"clusters": {
"2": [
{
"status": "INSTALLED",
"componentName": "NAMENODE",
"clusterId": "2",
"serviceName": "HDFS",
"command": "STATUS"
}
]
}
}
server收到这条心跳后,会把这个状态通过websocket通知前端,从下面的这个frame可以看到namenode已经从STARTED变成了INSTALLED
MESSAGE
destination:/events/hostcomponents
content-type:application/json;charset=UTF-8
subscription:sub-0
message-id:e0532345-e114-f209-23e2-d35d2f60d44a-21289
content-length:183
{
"hostComponents": [
{
"clusterId": 2,
"serviceName": "HDFS",
"hostName": "pbj-clickhouse-20-211.optaim.com",
"componentName": "NAMENODE",
"currentState": "INSTALLED",
"previousState": "STARTED"
}
]
}
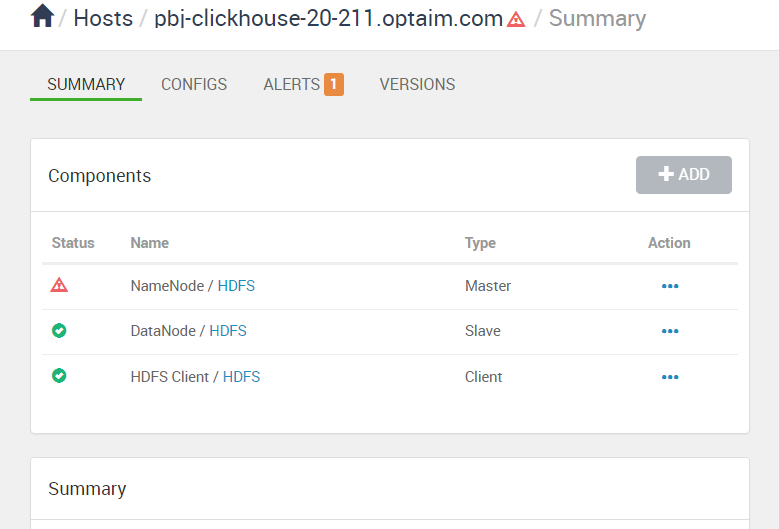
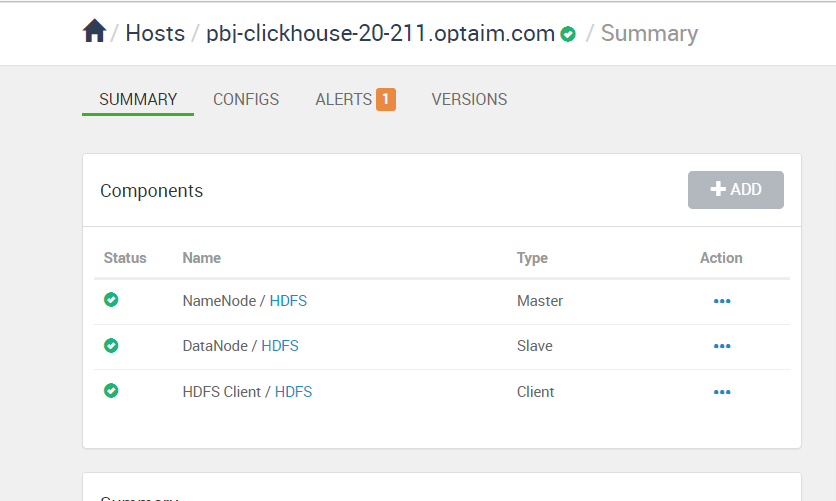
同时,由于不是由api触发的状态变化,ambari会尝试自动重启这个服务,几秒后会收到下面这个frame,可以看到NameNode已经恢复正常了
MESSAGE
destination:/events/hostcomponents
content-type:application/json;charset=UTF-8
subscription:sub-0
message-id:e0532345-e114-f209-23e2-d35d2f60d44a-21293
content-length:183
{
"hostComponents": [
{
"clusterId": 2,
"serviceName": "HDFS",
"hostName": "pbj-clickhouse-20-211.optaim.com",
"componentName": "NAMENODE",
"currentState": "STARTED",
"previousState": "INSTALLED"
}
]
}
Ambari的缺点
Ambari不符合Cloudera的商业利益,从2020年之后就不太活跃了,持续两年没有新版本发布,前景不明
因为Ambari之前都是配合HDP使用的,HDP的文档很完善,但是Ambari的文档相对比较少,而且比较旧,学习成本比较高,有问题基本只能靠看源码解决,但是设计相对比较优秀,代码层次比较清楚
由于依赖Hortonworks的库,无法直接编译,需要修改依赖(改为apache即可)
解耦工作还没彻底结束,无法直接使用自定义stack,需要做少量源码修改
Bigtop
Bigtop 是一个用于开发Apache Hadoop生态系统的打包和测试的项目。起源于Cloudera,后来贡献给了apache。
Bigtop的主要目标就是构建一个Apache Hadoop生态系统的包和交互式测试的社区。这个包括对各类不同级别工程进行测试(包,平台,运行时间,升级等),重点是整个系统,而不是单个项目。
Bigtop主要做的事:
- 解决hadoop生态的兼容性(或者说是互操作性)
- 封装成不同操作系统包管理器可以使用的包(rpm、deb等)
回忆一下Ambari定制,需要Stack+Repository,Bigtop就对应这里的Repository,他提供的是hadoop生态的安装包,解决了组件之间的兼容性
Bigtop不是为了代替CDH或者是HDP,社区自己的定位是hadoop供应商的上游,也就是说,下游的CDH和HDP可以基于Bigtop开发。在一段时间内也的确如此,CDH4.X和HDP 曾经某些版本都是基于Bigtop开发的,但是由于社区发布非常缓慢,CDH和HDP后来脱离了Bigtop,自己解决兼容性问题。
Bigtop最新发布版是3.0.0,2021-10-25发布
bigtop 3.0.0 stack includes the following components
alluxio 2.4.1
bigtop-groovy 2.5.4
bigtop-jsvc 1.0.15
bigtop-utils 3.0.0
elasticsearch 5.6.14
flink 1.11.3
gpdb 5.28.5
hadoop 3.2.2
hbase 2.2.6
hive 3.1.2
kafka 2.4.1
kibana 5.4.1
livy 0.7.1
logstash 5.4.1
oozie 5.2.1
phoenix 5.1.0
solr 8.7.0
spark 3.0.1
sqoop 1.4.7
tez 0.10.0
ycsb 0.17.0
zeppelin 0.9.0
zookeeper 3.4.14
bigtop的所有release:
| relaease | 发布时间 | hadoop的版本 |
|---|---|---|
| 0.1.0 | 2011-08 | |
| 0.2.0 | 2011-09 | |
| 0.4.0 | 2011-12 | |
| 0.5.0 | 2012-12 | 2.0.2 |
| 0.6.0 | 2013-06 | 2.0.5 |
| 0.7.0 | 2013-11 | 2.0.6 |
| 0.8.0 | 2014-12 | 2.2.0 |
| 1.0.0 | 2015-09-03 | 2.6.0 |
| 1.1.0 | 2016-02-17 | 2.7.1 |
| 1.2.0 | 2017-04-13 | 2.7.3 |
| 1.2.1 | 2017-11-25 | 2.7.3 |
| 1.3.0 | 2018-12-25 | 2.8.4 |
| 1.4.0 | 2019-06-18 | 2.8.5 |
| 1.5.0 | 2020-12-17 | 2.10.1 |
| 3.0.0 | 2021-10-25 | 3.2.2 |
也就是说Bigtop直到今年的10月底才开始支持hadoop 3.0,比CDH和HDP慢了3年多,而且发布间隔通常是半年至一年,基本不会发布小版本更新,因为Bigtop社区说他们主要解决的是生态的互操作性,他们不会为了修复某个组件的bug而发布一个小版本。CDH和HDP则是一个完整的解决方案,如果组件有bug,他们可能会发布一个小版本更新,通知用户升级。从这里能够看出来,作为商业版hadoop供应商,CDH和HDP 还是做了很多事情的。
Bigtop虽然发版很慢,但是如果不是为了商业发行的话,自用其实还是可以接受的。而且没有那么激进,需要我们自己解决的bug相对比较少。
结论
目前看来,数据平台(或者说是hadoop生态)这种平台层面,没有低成本的解决方案。导致目前国内使用CDH和HDP的公司主要分为以下几种:
- 上云,使用云服务厂商提供的解决方案
- 购买CDH企业版,付费
- 使用Apache发行版,组建平台层的团队进行二次开发及维护
- Amabri定制,或者CDH魔改(利用CDH扩展功能,Cloudera Manager不开源,改动有限,只能是延长使用时间)
- 坚守CDH和HDP免费版,不升级(躺平派,车到山前必有路)
相比较而言,Amabri定制是比较适合我们的公司的。
我们实现了一个最小的stack,并测试成功,证明使用Ambari定制是可行的。
虽然Amabri可能不会再更新,Bigtop发布又非常缓慢,但是Ambari定制+Bigtop这个方案是可以解决我们面临的问题的,同时这个方案也是目前看来成本相对比较小的。我们可以在这个IDP的基础上继续开发,最终达到生产可用的状态,彻底替换掉CDH。
附录
stomp
STOMP即Simple (or Streaming) Text Orientated Messaging Protocol,简单(流)文本定向消息协议,它提供了一个可互操作的连接格式,允许STOMP客户端与任意STOMP消息代理(Broker)进行交互。
stomp消息以frame来划分,借鉴了http的设计,每个frame分为三部分:command、header、body
header和body之间要空一行(LR),只有3个command(SEND、MESSAGE、ERROR)可以有body,其他command包含body无效
MESSAGE
destination:/events/hosts
content-type:application/json;charset=UTF-8
subscription:sub-5
message-id:0409c337-2888-e0a6-7186-4dfa7ddfef4f-14051
content-length:127
{
"cluster_name": "idp",
"host_name": "pbj-clickhouse-20-211.optaim.com",
"host_status": "ALERT",
"last_heartbeat_time": 1638842853146
}
stomp的command类型不多,只有以下几种
client-command = "SEND"
"SUBSCRIBE"
"UNSUBSCRIBE"
"BEGIN"
"COMMIT"
"ABORT"
"ACK"
"DISCONNECT"
server-command = "CONNECTED"
"MESSAGE"
"RECEIPT"
"ERROR"
stomp的生命周期主要分为三部分:CONNECT、SEND/MESSAGE、DISCONNECT
CONNNECT
客户端和服务端首先需要简历连接,连接由客户端发起,服务端返回CONNECTED (或者ERROR)
CONNECT
accept-version:1.1,1.0
heart-beat:10000,10000
CONNECTED
version:1.1
heart-beat:10000,10000
user-name:admin
ERROR
ERROR是服务端向客户端发送的特殊消息,可以任意时刻发送,发送ERROR意味着服务端会断开此次连接,并且是发送后立即断开,不会确认收到。这是最特殊的command,可以有body,通常body内包含错误信息
ERROR
receipt-id:message-12345
content-type:text/plain
content-length:170
message:malformed frame received
The message:
-----
MESSAGE
destined:/queue/a
receipt:message-12345
Hello queue a!
-----
Did not contain a destination header, which is REQUIRED
for message propagation.
SUBCRIBE、UNSUBCRIBE
这两个command是客户端发送给服务端的,用来注册或取消注册某个地址的监听事件,服务端会把这个地址的消息发送给订阅的客户端(就是上面的MESSAGE),这个可以没有回执,有的话就是RECEIPT
SUBSCRIBE
id:0
destination:/queue/foo
ack:client
RECEIPT
receipt-id:message-12345
SEND
SEND是客户端向服务端发送消息的command,可以有body
SEND
destination:/queue/a
content-type:text/plain
hello queue a
MESSAGE
MESSAGE是服务端向客户端发送消息的command,可以有body,接收的是ACK或者NACK(或者ERROR),然后服务端可以选择性回复RECERPT
MESSAGE
subscription:0
message-id:007
destination:/queue/a
content-type:text/plain
hello queue a
ACK
id:12345
transaction:tx1
RECEIPT
receipt-id:12345
BEGIN、COMMIT、ABORT
这几个命令是客户端发送给服务端,用来做原子性操作的,保证事务期间发送(SEND)或者确认的消息(ACK、NACK)全部成功或者全部失败,不做展开讲解
DISCONNECT
DISCONNECT是客户端发送给服务端用来主动断开连接的,服务端返回RECEIPT后连接断开
DISCONNECT
receipt:77
RECEIPT
receipt-id:77
因为websocket使用起来和tcp没啥区别,需要自己定义具体的消息交换协议,所以websocket+stomp算是目前的最佳实现