个人笔记
SongPinru 的小仓库
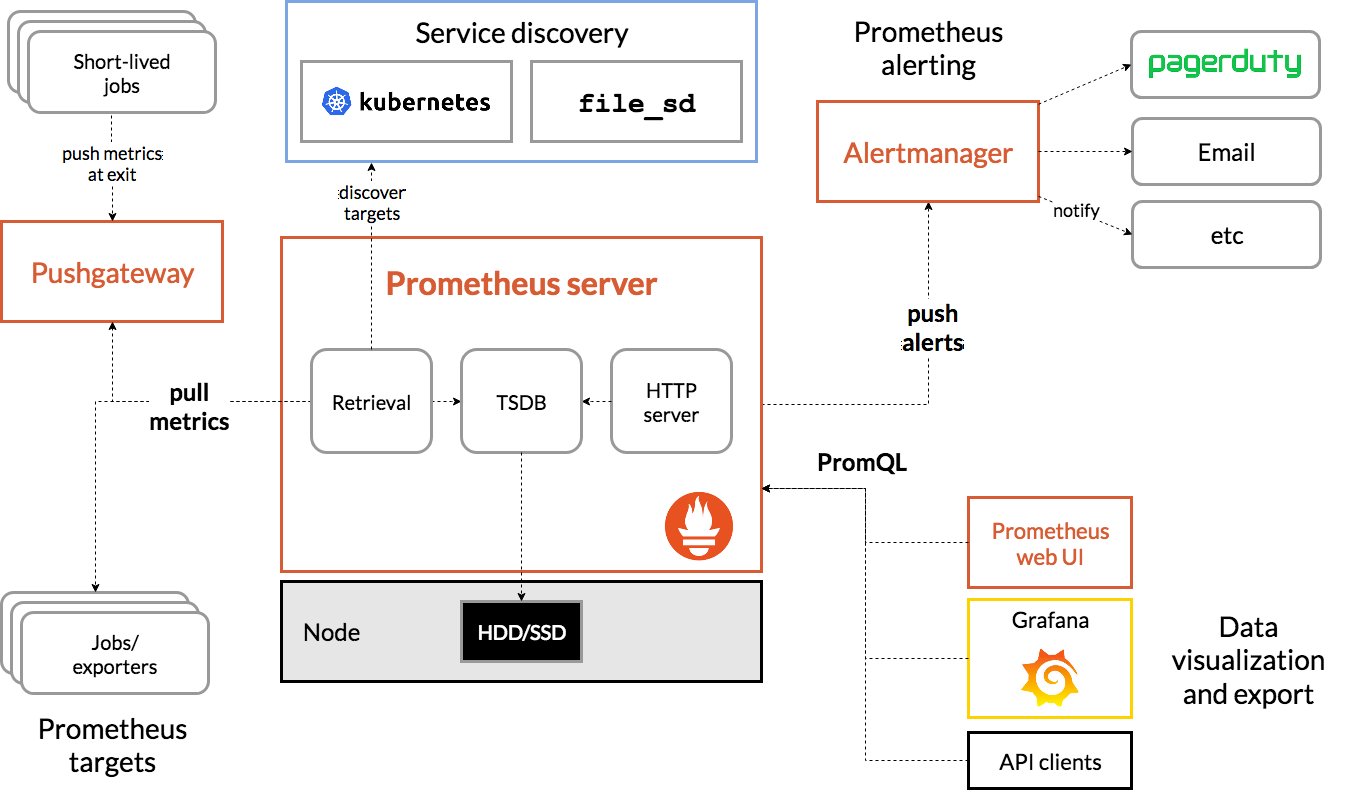
架构图
特点
- 一个多维数据模型,其中包含通过度量标准名称和键/值对标识的时间序列数据
- PromQL,一种灵活的查询语言 ,可利用此维度
- 不依赖分布式存储;单个服务器节点是自治的
- 时间序列收集通过HTTP上的拉模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持模式
组件
Prometheus生态系统由多个组件组成,其中许多是可选的:
- Prometheus server:prometheus主服务器,它会刮取并存储时间序列数据
- client libraries:用于检测应用程序代码,并构建Metric,然后通过Http公布
- pushgateway:一个支持短期工作的推送网关
- exporters :用client写好的报告器,可以直接使用。
- alertmanager:一个处理警报的工具
- 其他工具
配置
Server
PushGateway
Altermanager
存储
本地文件
拉取的数据按两小时分组。每个两个小时的时间段包含一个目录,该目录包含一个或多个块文件,该文件包含该时间窗口的所有时间序列样本,以及元数据文件和索引文件(该索引文件将度量标准名称和标签索引到块文件中的时间序列) )。通过API删除系列时,删除记录存储在单独的逻辑删除文件中(而不是立即从块文件中删除数据)。
用于输入样本的当前块保留在内存中,并且不会完全保留。当Prometheus服务器重新启动时,可以通过重播日志(WAL)防止崩溃。预写日志文件wal以128MB的段存储在目录中。这些文件包含尚未压缩的原始数据。因此,它们比常规的阻止文件大得多。Prometheus将至少保留三个预写日志文件。高流量的服务器可能会保留三个以上的WAL文件,以便保留至少两个小时的原始数据。
Prometheus服务器的数据目录如下所示:
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001//数据,按128M分段
│ ├── tombstones//删除的记录
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── chunks_head
│ └── 000001
└── wal
├── 000000002
└── checkpoint.00000001
└── 00000000
合并
最初的两个小时的块最终会在后台合并为更长的块。
压缩将创建更大的块,其中包含的数据最多占保留时间的10%或31天(以较小者为准)。
优化
Prometheus具有几个用于配置本地存储的标志。最重要的是:
--storage.tsdb.path:Prometheus写入数据库的位置。默认为data/。--storage.tsdb.retention.time:何时删除旧数据。默认为15d。storage.tsdb.retention如果此标志设置为默认值以外的其他值,则覆盖。--storage.tsdb.retention.size:[EXPERIMENTAL]要保留的最大存储块字节数。最旧的数据将首先被删除。默认为0或禁用。该标志是试验性的,将来的发行版中可能会更改。支持的单位:B,KB,MB,GB,TB,PB,EB。例如:“ 512MB”--storage.tsdb.retention:不推荐使用storage.tsdb.retention.time。--storage.tsdb.wal-compression:启用压缩预写日志(WAL)。根据您的数据,您可以预期WAL大小将减少一半,而额外的CPU负载却很少。此标志在2.11.0中引入,默认情况下在2.20.0中启用。请注意,一旦启用,将Prometheus降级到2.11.0以下的版本将需要删除WAL。
Prometheus每个样本平均只存储1-2个字节。因此,要计划Prometheus服务器的容量,可以使用以下粗略公式:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
PQL
Metric类型
在上一小节中我们带领读者了解了Prometheus的底层数据模型,在Prometheus的存储实现上所有的监控样本都是以time-series的形式保存在Prometheus内存的TSDB(时序数据库)中,而time-series所对应的监控指标(metric)也是通过labelset进行唯一命名的。
从存储上来讲所有的监控指标metric都是相同的,但是在不同的场景下这些metric又有一些细微的差异。 例如,在Node Exporter返回的样本中指标node_load1反应的是当前系统的负载状态,随着时间的变化这个指标返回的样本数据是在不断变化的。而指标node_cpu所获取到的样本数据却不同,它是一个持续增大的值,因为其反应的是CPU的累积使用时间,从理论上讲只要系统不关机,这个值是会无限变大的。
为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus定义了4中不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
在Exporter返回的样本数据中,其注释中也包含了该样本的类型。例如:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
Counter:只增不减的计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。 一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
Counter是一个简单但有强大的工具,例如我们可以在应用程序中记录某些事件发生的次数,通过以时序的形式存储这些数据,我们可以轻松的了解该事件产生速率的变化。 PromQL内置的聚合操作和函数可以让用户对这些数据进行进一步的分析:
例如,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)
Gauge:可增可减的仪表盘
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
通过Gauge指标,用户可以直接查看系统的当前状态:
node_memory_MemFree
对于Gauge类型的监控指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况。例如,计算CPU温度在两个小时内的差异:
delta(cpu_temp_celsius{host="zeus"}[2h])
还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例如,预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600)
使用Histogram和Summary分析数据分布情况
除了Counter和Gauge类型的监控指标以外,Prometheus还定义了Histogram和Summary的指标类型。Histogram和Summary主用用于统计和分析样本的分布情况。
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在0~10ms之间的请求数有多少而10~20ms之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标,我们可以快速了解监控样本的分布情况。
例如,指标prometheus_tsdb_wal_fsync_duration_seconds的指标类型为Summary。 它记录了Prometheus Server中wal_fsync处理的处理时间,通过访问Prometheus Server的/metrics地址,可以获取到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Prometheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
在Prometheus Server自身返回的样本数据中,我们还能找到类型为Histogram的监控指标prometheus_tsdb_compaction_chunk_range_bucket。
# HELP prometheus_tsdb_compaction_chunk_range Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range histogram
prometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="6400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="25600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="102400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="409600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260
prometheus_tsdb_compaction_chunk_range_bucket{le="6.5536e+06"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780
prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09
prometheus_tsdb_compaction_chunk_range_count 780
与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。
同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数。不同在于Histogram通过histogram_quantile函数是在服务器端计算的分位数。 而Sumamry的分位数则是直接在客户端计算完成。因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。在选择这两种方式时用户应该按照自己的实际场景进行选择。
查询
基础
http_request_total
http_request_total{}
{method="get"}
http_request_total{}[5m]
http_request_total{}[1d] offset 1d
{__name__=~"http_request_total"} # 合法
{__name__=~"node_disk_bytes_read|node_disk_bytes_written"} # 合法
(node_memory_bytes_total - node_memory_free_bytes_total) / node_memory_bytes_total > 0.95 #只显示大于0.95的
时间单位:
- s - 秒
- m - 分钟
- h - 小时
- d - 天
- w - 周
- y - 年
标签匹配运算符:
=:选择与提供的字符串完全相同的标签。!=:选择不等于提供的字符串的标签。=~:选择与提供的字符串进行正则表达式匹配的标签。!~:选择不与提供的字符串进行正则表达式匹配的标签。
数学运算符如下所示:
+(加法)-(减法)*(乘法)/(除法)%(求余)^(幂运算)
布尔运算符如下:
==(相等)!=(不相等)>(大于)<(小于)>=(大于等于)<=(小于等于)
使用bool修饰符改变布尔运算符的行为:
#布尔运算符的默认行为是对时序数据进行过滤。而在其它的情况下我们可能需要的是真正的布尔结果。例如,只需要知道当前模块的HTTP请求量是否>=1000,如果大于等于1000则返回1(true)否则返回0
http_requests_total > bool 1000
集合运算符:
and(交集))or(并集)unless(差集)
操作符中优先级由高到低依次为:
^*, /, %+, -==, !=, <=, <, >=, >and, unlessor
标签匹配:
on:只匹配这些标签相同的
ignore:忽略某些标签(只匹配剩下的)
group_left:左边是多
group_right:右边是多
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m
聚合
by:按照后面字段聚合
without:by的反例,除这些字段
sum(求和)min(最小值)max(最大值)avg(平均值)stddev(标准差)stdvar(标准差异)count(计数)count_values(对value进行计数)bottomk(后n条时序)topk(前n条时序)quantile(分布统计)
sum(prometheus_http_requests_total) by (code,handler)
只有count_values, quantile, topk, bottomk支持参数(parameter)
count_values("count", http_requests_total)
topk和bottomk则用于对样本值进行排序,返回当前样本值前n位,或者后n位的时间序列。
获取HTTP请求数前5位的时序样本数据,可以使用表达式:
topk(5, http_requests_total)
bottomk(5, http_requests_total)
quantile用于计算当前样本数据值的分布情况quantile(φ, express)其中0 ≤ φ ≤ 1。
例如,当φ为0.5时,即表示找到当前样本数据中的中位数:
quantile(0.5, http_requests_total)
内置函数
abs()absent()absent_over_time()ceil()changes()clamp()clamp_max()clamp_min()day_of_month()day_of_week()days_in_month()delta()deriv()exp()floor()histogram_quantile()holt_winters()hour()idelta()increase()irate()label_join()label_replace()ln()log2()log10()minute()month()predict_linear()rate()resets()round()scalar()sgn()sort()sort_desc()sqrt()time()timestamp()vector()year()_over_time()
HTTP API
瞬时查询
GET /api/v1/query
URL请求参数:
- query=:PromQL表达式。
- time=:用于指定用于计算PromQL的时间戳。可选参数,默认情况下使用当前系统时间。
- timeout=:超时设置。可选参数,默认情况下使用-query,timeout的全局设置。
区间查询
GET /api/v1/query_range
curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s'
URL请求参数:
- query=: PromQL表达式。
- start=: 起始时间。
- end=: 结束时间。
- step=: 查询步长。
- timeout=: 超时设置。可选参数,默认情况下使用-query,timeout的全局设置。
管理API
Prometheus提供了一组管理API,以促进自动化和集成。
健康检查
GET /-/healthy
该端点始终返回200,应用于检查Prometheus的运行状况。
准备检查
GET /-/ready
当Prometheus准备服务流量(即响应查询)时,此端点返回200。
重装
PUT /-/reload
POST /-/reload
该端点触发Prometheus配置和规则文件的重新加载。默认情况下它是禁用的,可以通过该--web.enable-lifecycle标志启用。
或者,可以通过向SIGHUPPrometheus进程发送a来触发配置重载。
放弃
PUT /-/quit
POST /-/quit
该端点触发Prometheus的正常关闭。默认情况下它是禁用的,可以通过该--web.enable-lifecycle标志启用。