个人笔记
SongPinru 的小仓库
基础语法
编码
默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。 当然你也可以为源码文件指定不同的编码:
# -*- coding: cp-1252 -*-
标识符
- 第一个字符必须是字母表中字母或下划线 _ 。
- 标识符的其他的部分由字母、数字和下划线组成。
- 标识符对大小写敏感。
python保留字
保留字即关键字,我们不能把它们用作任何标识符名称。Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释
Python中单行注释以 # 开头,实例如下:
#!/usr/bin/python3
# 第一个注释
print ("Hello, Python!") # 第二个注释
多行注释用三个单引号 ’’‘ 或者三个双引号 ””“ 将注释括起来,例如:
#!/usr/bin/python3
'''
这是多行注释,用三个单引号
这是多行注释,用三个单引号
这是多行注释,用三个单引号
'''
"""
这是多行注释,用三个双引号
这是多行注释,用三个双引号
这是多行注释,用三个双引号
"""
print("Hello, World!")
行与缩进
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
缩进的空格数是可变的,但是同一个代码块的语句必须包含==相同的缩进空格数==
缩进不一致,执行后会出现类似以下错误:
File "test.py", line 6
print ("False") # 缩进不一致,会导致运行错误
^
IndentationError: unindent does not match any outer indentation level
多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠()来实现多行语句,例如:
total = item_one + \
item_two + \
item_three
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠(),例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
记住:空行也是程序代码的一部分。
等待用户输入
执行下面的程序在按回车键后就会等待用户输入:
#!/usr/bin/python3
input("\n\n按下 enter 键后退出。")
同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割,以下是一个简单的实例:
#!/usr/bin/python3
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
我们将首行及后面的代码组称为一个子句(clause)。
如下实例:
if expression :
suite
elif expression :
suite
else :
suite
Print 输出
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end=”“:
#!/usr/bin/python3
x="a"
y="b"
# 换行输出
print( x )
print( y )
print('---------')
# 不换行输出
print( x, end=" " )
print( y, end=" " )
print()
import 与 from…import
在 python 用 import 或者 from…import 来导入相应的模块。
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
命令行参数
很多程序可以执行一些操作来查看一些基本信息,Python可以使用-h参数查看各参数帮助信息:
$ python -h
usage: python [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-c cmd : program passed in as string (terminates option list)
-d : debug output from parser (also PYTHONDEBUG=x)
-E : ignore environment variables (such as PYTHONPATH)
-h : print this help message and exit
[ etc. ]
基本数据类型
多个变量赋值
Python允许你同时为多个变量赋值。例如:
a = b = c = 1
以上实例,创建一个整型对象,值为 1,从后向前赋值,三个变量被赋予相同的数值。
您也可以为多个对象指定多个变量。例如:
a, b, c = 1, 2, "runoob"
标准数据类型
Python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
不可变数据(3 个):**Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):**List(列表)、Dictionary(字典)、Set(集合)
Number(数字)
Python3 支持 int、float、bool、complex(复数)。
在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
像大多数语言一样,数值类型的赋值和计算都是很直观的。
内置的 type() 函数可以用来查询变量所指的对象类型。
>>> a, b, c, d = 20, 5.5, True, 4+3j
>>> print(type(a), type(b), type(c), type(d))
<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
注意:在 Python2 中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True。到 Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加。
String(字符串)
Python中的字符串用单引号 ‘ 或双引号 “ 括起来,同时使用反斜杠 \ 转义特殊字符。
字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。第三个数是步长,为负表示翻转读取
加号 + 是字符串的连接符, 星号 ***** 表示复制当前字符串,与之结合的数字为复制的次数。
#!/usr/bin/python3
str = 'Runoob'
print (str) # 输出字符串
print (str[0:-1]) # 输出第一个到倒数第二个的所有字符
print (str[0]) # 输出字符串第一个字符
print (str[2:5]) # 输出从第三个开始到第五个的字符
print (str[2:]) # 输出从第三个开始的后的所有字符
print (str * 2) # 输出字符串两次,也可以写成 print (2 * str)
print (str + "TEST") # 连接字符串
反斜杠()可以作为续行符,表示下一行是上一行的延续。也可以使用 ”"”…””“ 或者 ’'’…’’‘ 跨越多行。
注意,Python 没有单独的字符类型,一个字符就是长度为1的字符串。
python字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ’%%’输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
Python三引号
python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。实例如下
#!/usr/bin/python3
para_str = """这是一个多行字符串的实例
多行字符串可以使用制表符
TAB ( \t )。
也可以使用换行符 [ \n ]。
"""
print (para_str)
f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
之前我们习惯用百分号 (%):
>>> name = 'Runoob'
>>> 'Hello %s' % name
'Hello Runoob'
>>> name = 'Runoob'
>>> f'Hello {name}' # 替换变量
>>> f'{1+2}' # 使用表达式
'3'
>>> w = {'name': 'Runoob', 'url': 'www.runoob.com'}
>>> f'{w["name"]}: {w["url"]}'
'Runoob: www.runoob.com'
数字格式化
下表展示了 str.format() 格式化数字的多种方法:
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | '{:b}'.format(11) '{:d}'.format(11) '{:o}'.format(11) '{:x}'.format(11) '{:#x}'.format(11) '{:#X}'.format(11) |
1011 11 13 b 0xb 0XB |
进制 |
^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
List(列表)
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
#!/usr/bin/python3
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]
tinylist = [123, 'runoob']
print (list) # 输出完整列表
print (list[0]) # 输出列表第一个元素
print (list[1:3]) # 从第二个开始输出到第三个元素
print (list[2:]) # 输出从第三个元素开始的所有元素
print (tinylist * 2) # 输出两次列表
print (list + tinylist) # 连接列表
Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
元组中的元素类型也可以不相同:
#!/usr/bin/python3
tuple = ( 'abcd', 786 , 2.23, 'runoob', 70.2 )
tinytuple = (123, 'runoob')
print (tuple) # 输出完整元组
print (tuple[0]) # 输出元组的第一个元素
print (tuple[1:3]) # 输出从第二个元素开始到第三个元素
print (tuple[2:]) # 输出从第三个元素开始的所有元素
print (tinytuple * 2) # 输出两次元组
print (tuple + tinytuple) # 连接元组
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
Set(集合)
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)
#!/usr/bin/python3
sites = {'Google', 'Taobao', 'Runoob', 'Facebook', 'Zhihu', 'Baidu'}
print(sites) # 输出集合,重复的元素被自动去掉
# 成员测试
if 'Runoob' in sites :
print('Runoob 在集合中')
else :
print('Runoob 不在集合中')
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素
集合运算
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False
>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
Dictionary(字典)
字典(dictionary)是Python中另一个非常有用的内置数据类型。
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
#!/usr/bin/python3
dict = {}
dict['one'] = "1 - 菜鸟教程"
dict[2] = "2 - 菜鸟工具"
tinydict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'}
print (dict['one']) # 输出键为 'one' 的值
print (dict[2]) # 输出键为 2 的值
print (tinydict) # 输出完整的字典
print (tinydict.keys()) # 输出所有键
print (tinydict.values()) # 输出所有值
构造函数 dict() 可以直接从键值对序列中构建字典如下:
>>> dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)])
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
>>> dict(Runoob=1, Google=2, Taobao=3)
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
>>>
注意:
- 1、字典是一种映射类型,它的元素是键值对。
- 2、字典的关键字必须为不可变类型,且不能重复。
- 3、创建空字典使用 { }。
Python数据类型转换
| 函数 | 描述 |
|---|---|
| [int(x [,base])] | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| [complex(real [,imag])] | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
运算符
Python算术运算符
以下假设变量a为10,变量b为21:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 31 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 |
| / | 除 - x 除以 y | b / a 输出结果 2.1 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 1 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的21次方 |
| // | 取整除 - 向下取接近商的整数 | >>> 9//2 4 >>> -9//2 -5 |
==注意:/返回的是float==
Python比较运算符
同java
Python赋值运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。 | 在这个示例中,赋值表达式可以避免调用 len() 两次:if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)") |
Python成员运算符
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
Python身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,求余数和取整除 |
| + - | 加法减法 |
| » « | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is/ is not | 身份运算符 |
| in/ not in | 成员运算符 |
| not /and /or | 逻辑运算符 |
流程控制
条件控制
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
while循环
#!/usr/bin/env python3
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("1 到 %d 之和为: %d" % (n,sum))
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
for循环
for <variable> in <sequence>:
<statements>
else:
<statements>
#!/usr/bin/python3
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
if site == "Runoob":
print("菜鸟教程!")
break
print("循环数据 " + site)
else:
print("没有循环数据!")
print("完成循环!")
#数字序列,前闭后开
for i in range(0, 10, 3)
迭代器和生成器
迭代器
迭代器有两个基本的方法:iter() 和 next()。
>>> list=[1,2,3,4]
>>> it = iter(list) # 创建迭代器对象
>>> print (next(it)) # 输出迭代器的下一个元素
1
>>> print (next(it))
2
>>>
迭代器对象可以使用常规for语句进行遍历:
#!/usr/bin/python3
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
#!/usr/bin/python3
import sys # 引入 sys 模块
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
while True:
try:
print (next(it))
except StopIteration:
sys.exit()
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
#!/usr/bin/python3
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print (next(f), end=" ")
except StopIteration:
sys.exit()
函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
参数传递
可更改(mutable)与不可更改(immutable)对象
- 可更改传递值
- 不可更改传递引用
默认参数
#!/usr/bin/python3
#可写函数说明
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print ("名字: ", name)
print ("年龄: ", age)
return
#调用printinfo函数
printinfo( age=50, name="runoob" )
print ("------------------------")
printinfo( name="runoob" )
不定长参数
加了星号 ***** 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。
#!/usr/bin/python3
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
print (vartuple)
# 调用printinfo 函数
printinfo( 70, 60, 50 )
加了两个星号 ** 的参数会以字典的形式导入。
#!/usr/bin/python3
# 可写函数说明
def printinfo( arg1, **vardict ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
print (vardict)
# 调用printinfo 函数
printinfo(1, a=2,b=3)
声明函数时,参数中星号 *** 可以单独出现,如果单独出现星号 *** 后的参数必须用关键字传入。
>>> def f(a,b,*,c):
... return a+b+c
...
>>> f(1,2,3) # 报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() takes 2 positional arguments but 3 were given
>>> f(1,2,c=3) # 正常
6
>>>
匿名函数
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
#!/usr/bin/python3
# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print ("相加后的值为 : ", sum( 10, 20 ))
print ("相加后的值为 : ", sum( 20, 20 ))
Python3.8 新增了一个函数形参语法 / 用来指明函数形参必须使用指定位置参数,不能使用关键字参数的形式。
在以下的例子中,形参 a 和 b 必须使用指定位置参数,c 或 d 可以是位置形参或关键字形参,而 e 或 f 要求为关键字形参:
def f(a, b, /, c, d, *, e, f):
print(a, b, c, d, e, f)
以下使用方法是正确的:
f(10, 20, 30, d=40, e=50, f=60)
遍历技巧
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
>>> for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
...
0 tic
1 tac
2 toe
同时遍历两个或更多的序列,可以使用 zip() 组合:
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print 'What is your {0}? It is {1}.'.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数:
>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
9
7
5
3
1
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted(set(basket)):
... print(f)
...
apple
banana
orange
pear
数据结构
模块
就是文件
#!/usr/bin/python3
# Filename: support.py
def print_func( par ):
print ("Hello : ", par)
return
- import …
- from … import …
- from … import *
__init__.py
这个文件是用来做模块或者包的初始化的,也是个python脚本,只要导了这个包,就会执行,里面可以放些变量函数,或者其他操作
import * 的内容为每次使用的值(必须全写),*的内容和all属性相关
__all__ = ["echo", "surround", "reverse"]
__name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
#!/usr/bin/python3
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
说明: 每个模块都有一个__name__属性,当其值是__main__时,表明该模块自身在运行,否则是被引入。
dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回:
>>> import fibo, sys
>>> dir(fibo)
['__name__', 'fib', 'fib2']
>>> dir(sys)
['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__',
'__package__', '__stderr__', '__stdin__', '__stdout__',
'_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe',
'_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv',
'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder',
'call_tracing', 'callstats', 'copyright', 'displayhook',
'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix',
'executable', 'exit', 'flags', 'float_info', 'float_repr_style',
'getcheckinterval', 'getdefaultencoding', 'getdlopenflags',
'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit',
'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount',
'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path',
'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1',
'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit',
'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout',
'thread_info', 'version', 'version_info', 'warnoptions']
如果没有给定参数,那么 dir() 函数会罗列出当前模块定义的所有名称:
输入和输出
- str(): 函数返回一个用户易读的表达形式。
- repr(): 产生一个解释器易读的表达形式。
str.format() 的基本使用
>>> print('{}网址: "{}!"'.format('菜鸟教程', 'www.runoob.com'))
菜鸟教程网址: "www.runoob.com!"
括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换。
在括号中的数字用于指向传入对象在 format() 中的位置,如下所示:
>>> print('{0} 和 {1}'.format('Google', 'Runoob'))
Google 和 Runoob
>>> print('{1} 和 {0}'.format('Google', 'Runoob'))
Runoob 和 Google
如果在 format() 中使用了关键字参数, 那么它们的值会指向使用该名字的参数。
>>> print('{name}网址: {site}'.format(name='菜鸟教程', site='www.runoob.com'))
菜鸟教程网址: www.runoob.com
位置及关键字参数可以任意的结合:
>>> print('站点列表 {0}, {1}, 和 {other}。'.format('Google', 'Runoob', other='Taobao'))
站点列表 Google, Runoob, 和 Taobao。
!a (使用 ascii()), !s (使用 str()) 和 !r (使用 repr()) 可以用于在格式化某个值之前对其进行转化:
>>> import math
>>> print('常量 PI 的值近似为: {}。'.format(math.pi))
常量 PI 的值近似为: 3.141592653589793。
>>> print('常量 PI 的值近似为: {!r}。'.format(math.pi))
常量 PI 的值近似为: 3.141592653589793。
可选项 : 和格式标识符可以跟着字段名。 这就允许对值进行更好的格式化。 下面的例子将 Pi 保留到小数点后三位:
>>> import math
>>> print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi))
常量 PI 的值近似为 3.142。
在 : 后传入一个整数, 可以保证该域至少有这么多的宽度。 用于美化表格时很有用。
>>> table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
>>> for name, number in table.items():
... print('{0:10} ==> {1:10d}'.format(name, number))
...
Google ==> 1
Runoob ==> 2
Taobao ==> 3
如果你有一个很长的格式化字符串, 而你不想将它们分开, 那么在格式化时通过变量名而非位置会是很好的事情。
最简单的就是传入一个字典, 然后使用方括号 [] 来访问键值 :
>>> table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
>>> print('Runoob: {0[Runoob]:d}; Google: {0[Google]:d}; Taobao: {0[Taobao]:d}'.format(table))
Runoob: 2; Google: 1; Taobao: 3
也可以通过在 table 变量前使用 ** 来实现相同的功能:
```python
>>> table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
>>> print('Runoob: {Runoob:d}; Google: {Google:d}; Taobao: {Taobao:d}'.format(**table))
Runoob: 2; Google: 1; Taobao: 3
读和写文件
open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
- filename:包含了你要访问的文件名称的字符串值。
- mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |

错误和异常
异常

try:
runoob()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')
抛出异常
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
raise [Exception [, args [, traceback]]]
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
>>> try:
raise NameError('HiThere')
except NameError:
print('An exception flew by!')
raise
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in ?
NameError: HiThere
断言
语法格式如下:
assert expression
等价于:
if not expression:
raise AssertionError
assert 后面也可以紧跟参数:
assert expression [, arguments]
等价于:
if not expression:
raise AssertionError(arguments)
以下实例判断当前系统是否为 Linux,如果不满足条件则直接触发异常,不必执行接下来的代码:
import sys
assert ('linux' in sys.platform), "该代码只能在 Linux 下执行"
# 接下来要执行的代码
面向对象
类对象
#!/usr/bin/python3
class MyClass:
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())
构造器
#!/usr/bin/python3
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i) # 输出结果:3.0 -4.5
self(可以换成其他字符串)代表类的实例,而非类
类的方法
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 实例化类
p = people('runoob',10,30)
p.speak()
继承
类后面的括号中写父类即可
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()
#多重继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
如果重写了__init__ 时,要继承父类的构造方法,可以使用 super 关键字:
super(子类,self).__init__(参数1,参数2,....)
还有一种经典写法:
父类名称.__init__(self,参数1,参数2,...)
类属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定是用 self。
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
类的专有方法:
-
__init__: 构造函数,在生成对象时调用 __del__: 析构函数,释放对象时使用__repr__: 打印,转换__setitem__: 按照索引赋值__getitem__: 按照索引获取值__len__: 获得长度__cmp__: 比较运算__call__: 函数调用__add__: 加运算__sub__: 减运算__mul__: 乘运算__truediv__: 除运算__mod__: 求余运算__pow__: 乘方
运算符重载
Python同样支持运算符重载,我们可以对类的专有方法进行重载,实例如下:
#!/usr/bin/python3
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print (v1 + v2)
命名空间和作用域
命名空间
一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
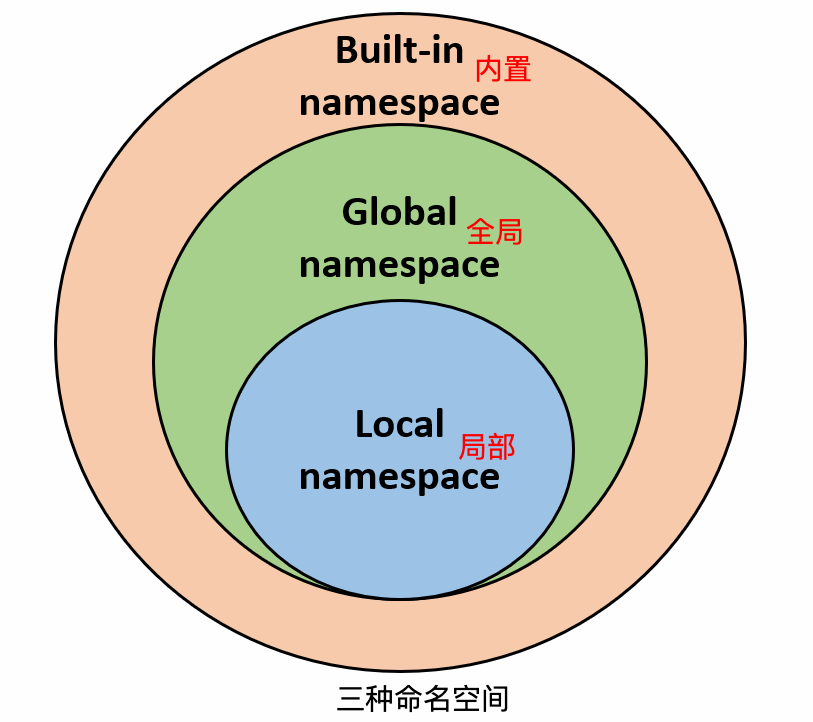
命名空间查找顺序:
假设我们要使用变量 runoob,则 Python 的查找顺序为:局部的命名空间去 -> 全局命名空间 -> 内置命名空间。
如果找不到变量 runoob,它将放弃查找并引发一个 NameError 异常:
NameError: name 'runoob' is not defined。
命名空间的生命周期:
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
因此,我们无法从外部命名空间访问内部命名空间的对象。
作用域
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问,如下代码:
>>> if True:
... msg = 'I am from Runoob'
...
>>> msg
'I am from Runoob'
>>>
实例中 msg 变量定义在 if 语句块中,但外部还是可以访问的。
全局变量和局部变量
- 局部变量: 定义在函数内部的变量
- 全局变量: 定义在函数外变量
global 和 nonlocal关键字
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字了。
以下实例修改全局变量 num:
#!/usr/bin/python3
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了,如下实例:
#!/usr/bin/python3
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
标准库概览
操作系统接口
os模块提供了不少与操作系统相关联的函数。
>>> import os
>>> os.getcwd() # 返回当前的工作目录
'C:\\Python34'
>>> os.chdir('/server/accesslogs') # 修改当前的工作目录
>>> os.system('mkdir today') # 执行系统命令 mkdir
0
建议使用 “import os” 风格而非 “from os import *“。这样可以保证随操作系统不同而有所变化的 os.open() 不会覆盖内置函数 open()。
在使用 os 这样的大型模块时内置的 dir() 和 help() 函数非常有用:
>>> import os
>>> dir(os)
<returns a list of all module functions>
>>> help(os)
<returns an extensive manual page created from the module's docstrings>
针对日常的文件和目录管理任务,:mod:shutil 模块提供了一个易于使用的高级接口:
>>> import shutil
>>> shutil.copyfile('data.db', 'archive.db')
>>> shutil.move('/build/executables', 'installdir')
文件通配符
glob模块提供了一个函数用于从目录通配符搜索中生成文件列表:
>>> import glob
>>> glob.glob('*.py')
['primes.py', 'random.py', 'quote.py']
命令行参数
通用工具脚本经常调用命令行参数。这些命令行参数以链表形式存储于 sys 模块的 argv 变量。例如在命令行中执行 “python demo.py one two three” 后可以得到以下输出结果:
>>> import sys
>>> print(sys.argv)
['demo.py', 'one', 'two', 'three']
错误输出重定向和程序终止
sys 还有 stdin,stdout 和 stderr 属性,即使在 stdout 被重定向时,后者也可以用于显示警告和错误信息。
>>> sys.stderr.write('Warning, log file not found starting a new one\n')
Warning, log file not found starting a new one
大多脚本的定向终止都使用 “sys.exit()”。
字符串正则匹配
re模块为高级字符串处理提供了正则表达式工具。对于复杂的匹配和处理,正则表达式提供了简洁、优化的解决方案:
>>> import re
>>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest')
['foot', 'fell', 'fastest']
>>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat')
'cat in the hat'
如果只需要简单的功能,应该首先考虑字符串方法,因为它们非常简单,易于阅读和调试:
>>> 'tea for too'.replace('too', 'two')
'tea for two'
数学
math模块为浮点运算提供了对底层C函数库的访问:
>>> import math
>>> math.cos(math.pi / 4)
0.70710678118654757
>>> math.log(1024, 2)
10.0
random提供了生成随机数的工具。
>>> import random
>>> random.choice(['apple', 'pear', 'banana'])
'apple'
>>> random.sample(range(100), 10) # sampling without replacement
[30, 83, 16, 4, 8, 81, 41, 50, 18, 33]
>>> random.random() # random float
0.17970987693706186
>>> random.randrange(6) # random integer chosen from range(6)
4
访问 互联网
有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从 urls 接收的数据的 urllib.request 以及用于发送电子邮件的 smtplib:
>>> from urllib.request import urlopen
>>> for line in urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl'):
... line = line.decode('utf-8') # Decoding the binary data to text.
... if 'EST' in line or 'EDT' in line: # look for Eastern Time
... print(line)
<BR>Nov. 25, 09:43:32 PM EST
>>> import smtplib
>>> server = smtplib.SMTP('localhost')
>>> server.sendmail('soothsayer@example.org', 'jcaesar@example.org',
... """To: jcaesar@example.org
... From: soothsayer@example.org
...
... Beware the Ides of March.
... """)
>>> server.quit()
注意第二个例子需要本地有一个在运行的邮件服务器。
日期和时间
datetime模块为日期和时间处理同时提供了简单和复杂的方法。
支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出。
该模块还支持时区处理:
>>> # dates are easily constructed and formatted
>>> from datetime import date
>>> now = date.today()
>>> now
datetime.date(2003, 12, 2)
>>> now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.")
'12-02-03. 02 Dec 2003 is a Tuesday on the 02 day of December.'
>>> # dates support calendar arithmetic
>>> birthday = date(1964, 7, 31)
>>> age = now - birthday
>>> age.days
14368
常用时间处理方法
- 今天
today = datetime.date.today() - 昨天
yesterday = today - datetime.timedelta(days=1) - 上个月
last_month = today.month - 1 if today.month - 1 else 12 - 当前时间戳
time_stamp = time.time() - 时间戳转datetime
datetime.datetime.fromtimestamp(time_stamp) - datetime转时间戳
int(time.mktime(today.timetuple())) - datetime转字符串
today_str = today.strftime("%Y-%m-%d") - 字符串转datetime
today = datetime.datetime.strptime(today_str, "%Y-%m-%d") - 补时差
today + datetime.timedelta(hours=8)
数据压缩
以下模块直接支持通用的数据打包和压缩格式:zlib,gzip,bz2,zipfile,以及 tarfile。
>>> import zlib
>>> s = b'witch which has which witches wrist watch'
>>> len(s)
41
>>> t = zlib.compress(s)
>>> len(t)
37
>>> zlib.decompress(t)
b'witch which has which witches wrist watch'
>>> zlib.crc32(s)
226805979
性能度量
有些用户对了解解决同一问题的不同方法之间的性能差异很感兴趣。Python 提供了一个度量工具,为这些问题提供了直接答案。
例如,使用元组封装和拆封来交换元素看起来要比使用传统的方法要诱人的多,timeit 证明了现代的方法更快一些。
>>> from timeit import Timer
>>> Timer('t=a; a=b; b=t', 'a=1; b=2').timeit()
0.57535828626024577
>>> Timer('a,b = b,a', 'a=1; b=2').timeit()
0.54962537085770791
相对于 timeit 的细粒度,:mod:profile 和 pstats 模块提供了针对更大代码块的时间度量工具。
测试模块
开发高质量软件的方法之一是为每一个函数开发测试代码,并且在开发过程中经常进行测试
doctest模块提供了一个工具,扫描模块并根据程序中内嵌的文档字符串执行测试。
测试构造如同简单的将它的输出结果剪切并粘贴到文档字符串中。
通过用户提供的例子,它强化了文档,允许 doctest 模块确认代码的结果是否与文档一致:
def average(values):
"""Computes the arithmetic mean of a list of numbers.
>>> print(average([20, 30, 70]))
40.0
"""
return sum(values) / len(values)
import doctest
doctest.testmod() # 自动验证嵌入测试
unittest模块不像 doctest模块那么容易使用,不过它可以在一个独立的文件里提供一个更全面的测试集:
import unittest
class TestStatisticalFunctions(unittest.TestCase):
def test_average(self):
self.assertEqual(average([20, 30, 70]), 40.0)
self.assertEqual(round(average([1, 5, 7]), 1), 4.3)
self.assertRaises(ZeroDivisionError, average, [])
self.assertRaises(TypeError, average, 20, 30, 70)
unittest.main() # Calling from the command line invokes all tests