个人笔记
SongPinru 的小仓库
第一章 Scala入门
1.1 scala 和 java 的关系
略
1.2 环境搭建
1.2.1 window 环境搭建
- 准备 java 环境
- 解压 zip
- 配置环境变量
- SCALA_HOME
- PATH
1.2.2 idea 环境搭建
-
安装支持 scala 开发的插件(装完重启)
-
创建 maven project
-
添加 scala 的支持

-
创建一个 object

注:object 类等价于 java 中的静态类。
-
创建 main 函数 (main, 提示, 回车)
1.2.3 关联源码
-
解压源码,最好和 scala 的安装的目录在一起,方便管理
-
关联
1.2.4 HelloWorld.class
实现逻辑如下:
-
传统意义上的入口main方法被编译在HelloWorld.class中
-
在HelloWorld.class中的main方法中, 会访问HelloWorld$.class中的静态字段MODULE$ (这个字段的类型就是HelloWorld$) , 并使用这个字段调用HelloWorld$中的main方法。HelloWorld 中的逻辑有点像下面这样(以下伪代码旨在说明原理, 并不符合 java 或 scala 的语法):
public class HelloWorld{
public static void main(String[] args){
HelloWorld$.MODULE$.main(args);
}
}
- 真正打印字符串 “HelloWorld” 的逻辑在HelloWorld$中。 这个类有一个main实例方法, 来处理打印字符串的逻辑, 并且该类中有一个HelloWorld$类型的静态字段MODULE$ 。 上面的HelloWorld类中的入口main方法, 正是通过这个字段调用的HelloWorld$的main实例方法来打印”HelloWorld” 。HelloWorld$中的代码有点像这样(以下伪代码旨在说明原理, 并不符合java或scala的语法):
public final class HelloWorld${
public static final HelloWorld$ MODULE$ = new HelloWorld$();
public void main(String[] args){
println("HelloWorld");
}
}
第二章 变量与数据类型
2.1 变量和常量
scala中如何声明变量和常量:
变量
var a: Int = 20
注意: 变量声明的时候必须初始化. 不能延后初始化
当使用变量的再去声明.
常量
val c: Int = 10
注意: 1. 必须声明的时候进行初始化scala
2. 不能重新赋值 b = 200 ×
//实际开发的时候, 能用常量的地方, 绝对不要用变量.
类型推导
var a = 30
1. 如果在声明的时候没有指定类型, 则会根据初始化的值自动进行类型的推导。
2. 不要理解成动态类型。
3. 类型推导不是万能, 有些情况不能推导。
2.2 标识符的命名规范
- 按照 java 的规范 (数字字母)
- 下划线的使用要注意, 在 scala 中下划线有很多特殊的含义
- 可以使用所谓的的运算符作为标识符
+ - * /…- 至少两个,而且不能和字母混用
-
如果有必要,其实还可以使用任意的字符作为标识符
反引号括起来
2.3 字符串的输出
// 1. 使用java的输出
System.out.println("abc");
// 2. scala的输出
println("abc")
// 3. 格式化输出
val a = 20
// println("a = " + a)
// 参考的传统的c语言
printf("a = %d %s %.2f", a, "1128班", math.Pi)
2.3.1 字符串插值
s 插值(重要)
val a = 10
val b = 20
s"a = ${a * 10}, b= ${b * 100}"
raw 插值
val r = raw"\r \n \t"
2.3.2 字符串模板(多行字符串)
val sql =
"""
|select
| *
|from user
|where id > 10
|""".stripMargin
- 多行字符串配合字符串插值使用非常的方便
2.3.3 从键盘读取数据
// 从键盘读数据
// 1. java: 使用System.in直接读, 做一些封装
val reader = new BufferedReader(new InputStreamReader(System.in))
val line: String = reader.readLine()
println(line)
// 2. java: jdk 1.5之后, Scanner
val scanner = new Scanner(System.in)
val line2: String = scanner.nextLine()
println(line2)
// 3. ------------------------------ scala ---------------------------------
// println("请输入你的银行卡密码: ")
val line3: String = StdIn.readLine("请输入你的银行卡密码: ")
println(line3)
2.4 数据类型
2.4.1 java 的数据类型
-
基本数据类型
八大基本数据类型: byte short int long char(0-65535) float double boolean -
引用数据类型 (对象、数组、String、基本类型的包装类)
2.4.2 scala 的数据类型
Any
AnyVal 值类型
对应着java的基本类型
AnyRef 引用类型
-
Unit
java 中 void (方法不需要返回值的时候, 使用void) 关键字
Unit 类有且只有一个实例 (),用来替换 java 中的那个 void
Int -> 1, 2 ...Unit -> ()只要数据类型是 Unit,从语法上可以赋任何值,但是均不会改变其值为 ()。
-
Null
java: User a = nullscala: Null 类型, 它有一个值 null可以赋值给任何引用类型(包括 String,scala 中的 String 就是 java 中的 String,注意不是StringOPS)
-
Nothing
是 scala 中, 最底层的类型,是任何类型的子类型,而且没有任何的对象。
一般用于辅助类型的推导。当代码非正常结束,则值就是 nothing。
val v = StdIn.readDouble() // 若触发了异常,则返回值类型为 Nothing,而 Nothing 为任何类的子类,因此语法通过 val root: Double = if(v > 0) Math.sqrt(v) else throw new IllegalArgumentException println(root)
2.4.3 类型转换
-
自动类型转换(类型的提升)
从范围小的 -> 范围大的,才会自动转换
Byte -> Short -> Int -> Long -> Float -> DoubleChar -> Int->.... -
强制类型转换
.toInt .toDouble... -
和String之间的转换
- 值-> string .toString
- String->值 .toInt、.toDouble、.toBoolean …
2.4.4 判断相等
java中有2个用来判断相等
==
引用类型判断是地址值
equals
判断的是内容
scala中有3个用来判断相等:
== 和 equals
完全一样. 都是判断内容. 关键是看 equals 的实现
覆写的时候, 还是按照 java 的规矩来, 需要覆写 equals
eq
等价于java中的 ==
查看变量地址:
System.identityHashCode(变量名)
第三章 运算符
① 在 scala 中,本质上是没有运算符的,运算符的本质其实是方法名。
② 在 scala 中调用方法时,可以省略点;如果参数只有一个或者没有,则 ( ) 括号也可以省略。
③ 当省略了点和圆括号之后,方法名就是运算符了。
方法和运算符的区别:
- 调用方法必须有点;运算符是省略点的。
- 调用方法是没有优先级,就是按照调用顺序来执行;运算符有优先级。
注意:Scala 中没有 ++、– 操作符,需要通过 +=、-= 来实现同样的效果;没有三元运算符,需要使用 if 来实现。
第四章 流程控制
4.1 顺序控制
4.2 分支控制
4.2.1 java 的分支控制
-
if else -
switch(1)限制太多
switch(值){ case 常量: break; case 常量: }值的类型是有限制:
byte, char, int, short, enum, String(1.7新增),且 case 后面必须是常量。(2)存在
case穿透问题忘记添加
break则会导致case穿透
4.2.2 scala 的分支控制
-
if else
用法和 java 完全一样,但是多了一个功能:if 语句可以有返回值,返回值为执行的分支中最后一行代码的值。
-
模式匹配,不弱于 switch,后面的章节进行讲解。
在 scala 中,任何的语法结构都有值。
- 针对 if 语句来说,if 语句值是执行的分支中的最后一行代码的值。
- 赋值语句 ( =,+=, …) 作为一个语法结构也有值,但是它的值是 Unit 类型。
个人理解:Scala 中一切皆函数,一切函数皆有返回值类型。
4.3 循环结构
4.3.1 java 的循环结构
- for
- while
- do … while
4.3.2 scala 的循环结构
-
whilewhile的使用方式和 java 完全一样。循环语句的值是 Unit 类型,因此它的值没有任何的用处。
-
do ... whiledo ... while的使用方式也和 java 完全一样。
4.3.3 for 循环重点介绍
在 scala 中, for的本质不是一种循环,而是一种遍历。for 的本质是遍历集合,因此如果要用 for,需要先构建一个集合。
构建方式:
1.to(100) // 本质
1 to 100 // [1, 100]
1 until 100 // [1, 100)
1 until 1 // 结果为空集
1 until -1 // 结果为空集
步长定义:
// 定义步长为2,以下两种方式等价
1 to (100, 2)
1 to 100 by 2
100 to 1 by -1
其他特性:
-
退出循环 (本质是抛异常和捕捉异常)
import scala.util.control.Breaks._ breakable { // 也是 Breaks 类的一个方法, 内部其实 try 了抛出的异常 for (i <- 2 until n) { if (n % i == 0) { isPrime = false break // 抛出异常. 其实是 Breaks 类的一个方法, 内部在抛异常 } } } -
引入变量
for 循环中的循环变量其实为常量 val,不能手动对其进行修改;且这些变量具有不同的地址。类似地,scala 中很多情况下定义的变量如果没有指定 var,那么都是 val。
for (i <- 1 to 100; j = "aa"; k = "bb") println(s"$i $j $k") -
循环嵌套 (所有的代码都在内层循环)
// 案例:打印九九乘法表 for(i <- 1 to 9; j <- 1 to i){ print(s"$j * $i = ${i * j}\t") println() } -
for 守卫
// for守卫. 类似于 java 中的 continue for (n <- 1 to 100 if n % 2 == 0) { println(n) } -
for 推导:使用 yield 创建新的序列
// 新序列的数据类型与原序列的数据类型一致 def main(args: Array[String]): Unit = { val ints = for (i <- 1 to 100) yield i * i for (i <- ints) println(i) }4.3.4 案例:打印三角形
object PrintTriangle {
def main(args: Array[String]): Unit = {
printTriangle()
printTriangle(10)
}
def printTriangle(num: Int = 5) = {// 默认参数
for (i <- 1 to num) {
print(" "*(num - i)) // 字符串乘法
print("*"*(2 * i - 1))
println()
}
}
}
第五章 函数式编程
5.1 面向对象与函数式编程
对面向对象的理解:
代码(程序)的作用: 1. 暂存数据。 2. 对数据做各种运算, 得到想要结果。
面向过程: 定义变量(存储数据), 定义函数(做运算)
面向对象: 用对象进行封装,同时实现存储和运算的功能
对象其实是对数据和行为的封装
类: 更加方便地封装对象
函数式编程:
函数只封装了行为,没有封装数据
scala 完美融合了面向对象和函数式编程。scala 中一切皆函数。函数就是一等公民, 可以做为参数传递, 也可以作为返回值返回。
在科学领域, 用函数式比较方便, 在工程领域用面向对象比较方便。
编程的时候, 可以使用函数式编程风格, 也可以使用面向对象的编程风格。两种结合使用, 整个工程整体采用面向对象, 具体到某些代码更加函数式。
5.2 基本语法
关于函数定义:
1. 如果没有 return, 则自动把最后一行的值返回。
2. 如果函数实现只有一行代码, 则 { } 可以省略。
3. 如果函数内部没有使用 return, 则返回值的类型也可以省略, scala 编译器会根据
最后一行得到值的类型进行自动推导。(但定义式中的等号 “=” 不能省,否则为 Unit)
4. 如果在调用函数的时候, 如果没有参数则圆括号可以省略(即定义时可以没有圆括号)。
关于返回值:
1. 如果没有 return, 则自动把最后一行的值返回。
2. 如果有 return, 则代码执行到 return 会结束函数, 返回 return 后面的值。
但这个时候返回值类型就不能自动推导了。
3. 如果函数的返回值声明为 Unit, 那么无论 return 的值是什么, 返回的都是 Unit。
4. 如果返回值是 Unit, 那么这个时候, 其实可以省略掉 :Unit= , 即所谓的 “过程”。
但是 { } 不能省。
关于声明:
1. 在声明的时候, 如果参数的个数是 0, 那么声明时的圆括号也可以省略。
这个时候调用的时候, 圆括号就必须省略。
注:前提是这个函数不会当做参数进行传递,不然的话会引起歧义。即传参时,编译器不清楚传的是函数名还是函数调用后的结果值。
5.3 案例:求 1000 以内素数之和
object FunctionTest2 {
def main(args: Array[String]): Unit = {
println(sumPrime(0, 1000))
println(sumPrime2(0, 1000).sum)
}
def isPrime(num: Int): Boolean = {
if (num < 2) false
else {
for (i <- 2 until num if num % i == 0) return false
true
}
}
def sumPrime(start: Int, end: Int): Int = {
var sum = 0
for (i <- start to end if isPrime(i)) sum += i
sum
}
// 简化版
def sumPrime2(start: Int, end: Int) = for (i <- start to end if isPrime(i)) yield i
}
5.4 函数的其他特征
-
函数的形参参数的传入函数体后都是 val 常量。如果想改,应该自己重新声明一个新的变量,更改自己的新的变量。
-
可以在函数内定义新的函数。
注意:在函数内定义的函数,一般需要先定义再调用。
-
定义函数的时候,可以给函数设置默认值,当传递参数的时候,如果没有给这个有默认值的传递,则会使用默认值作为这个参数的值。建议将默认值放在参数列表的后方,不然给非默认参数赋值时需要对前面的所有参数赋值,这一点和 python 类似。
def add(a: Int, b: Int = 100) = a + b -
命名参数
位置参数 / 命名参数
println(add1(b = 2000, a = 1000))注意:
- 默认值出现在函数声明的处,位置参数出现在函数调用的地方
- 命名参数和默认值可以配合起来使用
-
可变参数
object MultiParameter { def main(args: Array[String]): Unit = { println(add(1)) println(add(1, 2)) println(add(1, 2, 3)) val ints = Array(1, 2, 3, 4) // 注意:数组传入时要使用 “: _*” 转为参数序列 println(add(ints: _*)) } def add(ss: Int*): Int ={ var sum = 0 for (i <- ss) sum += i sum } } // 若至少传一个参数,可以按照以下方式处理 def main(args: Array[String]): Unit = { println(add(1)) println(add(1, 2)) println(add(1, 2, 3)) val ints = Array(1, 2, 3, 4) println(add(1, ints: _*)) } def add(a: Int, ss: Int*): Int ={ var sum = 0 for (i <- ss) sum += i sum + a }注意:
-
在 java 中可以把数组直接传给可变参数
-
在 scala 中, 不能把数组直接传给可变参数。需要把数组展开之后,再传递
foo(arr:_*)
-
5.5 高阶函数
函数式编程标配:
1. 高阶函数
如果一个函数A接受一个或多个函数作为参数, 或者返回值是函数, 这样的函数A就叫高阶函数
2. 闭包
3. 柯里化
5.5.1 简单案例
object HighOrderFun {
def main(args: Array[String]): Unit = {
def abc(a: Int)= a + 10
val i = foo(abc)
println(i)
}
// 传一个函数名作为参数,并在函数体中调用传进来的函数
// 通过参数类型和返回值类型限定函数类型,多个参数需要用括号括起来
def foo(f: Int => Int) = {
f(10)
}
}
5.5.2 匿名函数
定义:没有名字的函数,就叫匿名函数。标准定义式为:
匿名函数的参数列表 => 匿名函数的实现
作用:一般用于向高阶函数传递函数参数
返回值类型:一般由编译器自动推导
注意:不要在匿名函数中使用 return
-
作为值存储在变量中
val f = (a: Int) => a + 10 val f1 = (a: Int, b:Int) => a + b val f2 = () => println(".....") -
给高阶函数传值
object Calc { def main(args: Array[String]): Unit = { // 定义函数传递1 def add(a: Int, b: Int) = a + b println(calc(1, 2, add)) // 匿名函数赋值传递 val f: (Int, Int) => Int = (a: Int, b: Int) => a + b println(calc(1, 2, f)) // 匿名函数直接传递 println(calc(1, 2, (a: Int, b: Int) => a + b)) // 省略参数类型(上下文推导) println(calc(1, 2, (a, b) => a + b)) // 省略参数名 println(calc(1, 2, _ + _)) } // 定义高阶函数 def calc(a: Int, b: Int, f: (Int, Int) => Int) = { f(a, b) } }
小结:=> 用法
1. 定义函数类型:
(参数类型) => 返回值类型,例如 f: Int => Int
2. 定义匿名函数:
(匿名函数的参数列表) => 匿名函数的实现, 例如 (a: Int, b:Int) => a + b
3. 类的自身类型
5.5.3 高阶函数的具体使用
object HighApplication {
def main(args: Array[String]): Unit = {
val arr = Array(10, 20, 30, 40, 50, 60)
foreach(arr, println)
foreach(filter(arr, _ > 30), println)
foreach(map(arr, _ * 10), println)
println(reduce(arr, _ + _))
}
def foreach(arr: Array[Int], op: Int => Unit)={
for (ele <- arr) op(ele)
}
def filter(arr: Array[Int], condition: Int => Boolean): Array[Int] = {
for (ele <- arr if condition(ele)) yield ele
}
def map(arr: Array[Int], op: Int => Int): Array[Int] = {
for (ele <- arr) yield op(ele)
}
def reduce(arr: Array[Int], op: (Int, Int) => Int): Int = {
var last = arr(0)
for (i <- 1 until arr.length) last = op(last, arr(i))
last
}
5.5.4 闭包函数
(1)一个匿名函数和这个匿名函数所处的环境就叫闭包。 (2)闭包可以延长外部局部变量的声明周期。 (3)闭包实现了在函数的外部访问函数的局部变量。
// 闭包函数的实质是在匿名函数返回时,根据其所处的环境对其参数做一个 “快照”。在接下来的生命周期里,“快照” 依然生效并可在此基础上继续操作。
object Closure {
def main(args: Array[String]): Unit = {
val f1 = foo(10)
// foo 调用结束后,a 的值依然存在,直至 f1 调用结束
println(f1(1))
}
def foo(a: Int)={
// 传入的参数 a 为下方的匿名函数赋值,下方的函数为闭包函数
b: Int => a + b
}
}
5.5.5 柯里化
def add(a:Int, b:Int) = a + b
// 柯里化后:
def add(a:Int)(b:Int) = a + b
// 应用案例
object Currying {
def main(args: Array[String]): Unit = {
/* val f1 = add(10)
println(f1(1))*/
println(add(10)(20))
}
/* def add(a: Int) ={
b: Int => a + b
}*/
def add(a: Int)(b: Int) = a + b
}
定义:将一个参数列表的多个参数变成多个参数列表的过程,就叫对函数柯里化(currying)
具体应用:柯里化一般只会柯里化出来两个参数列表。 第一个参数列表一般是必须要传入的参数。 第二个参数列表一般是定义隐式参数,将来如果不传,scala 会自动找隐式值去传。
柯里化的理论基础是闭包。
5.5.6 控制抽象
-
名调用
一般如果接受的是一个无参的函数(可以有返回值),可以改成名调用。名调用即直接将待调用的代码传入函数实施调用。
// 直接调用,需定义函数并传入 def foo(a: () => Int) = { a() a() a() } // 使用名调用进行改造,只需将代码块传入即可 def foo(a: => Int) = { a a a } // 注:println(代码块)先执行代码块内容,再将代码块返回值打印出来。案例:使用控制抽象实现 while 的功能
object MyWhileDemo { def main(args: Array[String]): Unit = { val arr = Array(10, 20, 30, 40, 50, 60) var sum = 0 var i = 0 myWhile(i < arr.length){ sum += arr(i) i += 1 } println(sum) } def myWhile(condition: => Boolean)(op: => Unit): Unit ={ if (condition){ op myWhile(condition)(op) } } } -
值调用
值调用是先将待调用部分运行出结果,之后再将结果进行调用。
5.5.7 惰性求值
lazy val a = 10
a 就会惰性求值
注意: 惰性求值只能用在val上
// lazy 其实是介于 val 和 def 之间的状况
object LazyDemo {
// 类变量随着类的加载自动执行且只执行一次
val a = {
println("a************")
100
}
// 惰性变量使用时执行,且只执行一次
lazy val b = {
println("b************")
100
}
// 函数每次调用时均执行一次
def c = {
println("c************")
100
}
def main(args: Array[String]): Unit = {
println(a)
println(a)
println(b)
println(b)
println(c)
println(c)
}
}
注意:scala 中代码块有返回值,返回值为代码块执行到最后一行的值,因此代码块可以赋值给变量,而且仅仅在变量加载的时候执行一次。这一点与 java 有所不同。
5.6 递归
普通的递归, 容易出现栈内存溢出。scala 提供了一种尾递归优化,可以避免栈内存溢出。
尾递归: 如果递归调用的时候,只有递归调用,不需要任何其他的运算,scala 中会进行尾递归优化,会把尾递归在编译的时候优化成循环。
注意:编写递归函数的时候,一定要清楚你个函数在干什么、各个参数表示什么含义、返回值表示什么含义、最好把注释写明白。
注意:递归函数的返回值不能推导。
object Recursive {
def main(args: Array[String]): Unit = {
// println(factorialTail(5))
// println(fibonacci(8))
println(fibonacciTail(8))
}
// 普通递归计算阶乘
def factorial(num: Int): Int = {
if (num == 1) 1
else num * factorial(num - 1)
}
@tailrec
def factorialTail(num: Int, product: Int = 1): Int = {
if (num == 1) product
else factorialTail(num - 1, product * num)
}
// 普通递归计算斐波那契数列
// 1, 1, 2, 3, 5, 8, 13, 21
def fibonacci(num: Int): Int = {
if (num == 1 || num == 2) 1
else fibonacci(num - 1) + fibonacci(num - 2)
}
// 尾递归计算斐波那契数列
// n: 序号,用来计数 f1:前面第二个, f2:前面第一个, f1 + f2:当前结果
// f(5, 1, 1)
// f(4, 1, 2)
// f(3, 2, 3)
// f(2, 3, 5)
// f(1, 5, 8) => 5
@tailrec
def fibonacciTail(n: Int, f1: Int = 1, f2: Int = 1): Int = {
if (n == 1) f1
else fibonacciTail(n - 1, f2, f1 + f2)
}
}
5.7 函数和方法的区别
方法和函数的区别:
1. 定义方式不一样
a: 方法定义
def 方法名(参数类别): 返回值类型 = { // 方法的实现 }
例如:def foo(a: Int, b:Int) = {
}
b: 函数定义
(参数列表) => { //函数体}
例如:(a: Int, b:Int) => a + b
2. 有匿名函数, 但是没有匿名方法
匿名函数 (a: Int, b:Int) => a + b
3. 函数也可以有名字
val/var f: (Int, Int) => Int = (a: Int, b: Int) => a + b
f 就是函数名
4. 方法调用的时候, 如果参数只有一个或者没有参数则圆括号可以省略,前提是类名不能省略。
函数的圆括号不能省略。
// foo2是方法
MethodFunction foo2 10
MethodFunction.foo2(10)
this foo2 10
// f1是函数, 则调用的不能省略圆括号
val f1 = () => println("无参函数...")
f1()
5. 函数可以作为值传递和作为返回值返回, 但是方法不行
换句话说, 在给高阶函数传递参数的时候, 原则上只能传函数, 不能传方法.
6. 在使用的时候, 不产生歧义的情况下, scala会自动的根据需要把方法转成函数。
手动转:
方法 add10 手动转函数: val a = add10 _
7. 方法可以重载/覆写, 函数不能重载/覆写
8. 以后使用的时候, 不用关注他们的区别, 就把函数和方法当成一个东西来使用。如果发现编译不通过, 就改成比较完整的写法。
5.8 部分应用函数
val square: Double => Double = Math.pow(_, 2)
println(square(3))
// 注意:类型不要推导
// println(_) 的本质也是部分应用,还可以在 _ 后方添加修饰,限制传参类型
val f: Int => Unit = println(_ :Int)
println(_ * 2) 会报错,因为传 “_” 时编译器会优先将其视为部分应用函数解析,并将 _ + 100 补充成 x => x + 100,最终传给 println() 的是 println(x => x + 100)。
// 部分应用函数参数位置只能传 _
补充 expand:
把 x => func(x) 简化为 func _ 或 func 的过程称为 eta-conversion
把 func 或 func _ 展开为 x => func(x) 的过程称为 eta-expansion
第六章 面向对象
6.1 面向对象 3 大特征
① 封装 ② 继承 ③ 多态
scala的面向对象理论和java完全一样, 具体实现方式不一样。
6.2 类和对象
6.2.1 定义类
[修饰符] class 类名 {
类体
}
// 案例
class User1{
// 只读属性
val sex = "male"
// 可读可写属性 _ 表示给 name 初始化默认值 null
var name: String = _
var age = 10
// 给类定义方法
def eat() = {
println(name) // 函数式角度
println(this.name) // 面向对象的角度
}
属性的默认初始化值:
- 数字 0
- 布尔型 false
- 引用型 null
6.2.2 特征
-
类和 java 一样,默认有空参构造器。但是一旦定义了有参构造器,就不会再默认提供空构造器了。
-
给类定义的所有的属性本质上都是私有的。
-
scala 会给这些私有属性添加公共的
getter或setter。// 反编译后的代码 public class com.jeffery.scala1128.day04.obj.User2 { private java.lang.String name; // var 为 private 属性 private final int age; // val 为 private final 属性 public java.lang.String name(); // getter public void name_$eq(java.lang.String); // setter public int age(); // val 只有 getter,没有setter public com.jeffery.scala1128.day04.obj.User2(java.lang.String, int);//构造器 } -
在访问属性的时候,其实是访问公共的
getter方法println(user.name) 其实是访问的 public java.lang.String name(); -
在修改属性值的时候, 会默认访问
setter方法user.name = "zs" 其实访问的是 public void name_$eq(java.lang.String)
6.2.3 构造器
// 构造器更像是构造函数,将需要传值的属性放到函数参数列表里。
// “函数体”(即类体)中不需要在对上述属性再次进行定义。
// 支持默认参数
class User2(var name: String, val age: Int = 8){
def eat = println(name)
}
-
在主构造中,如果某参数没有使用
val/var修饰,那么这个参数在有些情况 (在类内部地方用到) 下也会成为属性,但是是私有属性,而且是 final 修饰,没有提供公共的 getter 和 setter;如果某参数没有使用
val/var修饰,也没有在类的内部使用到,那么该参数对应的属性不会出现在反编译后的 java 类中,因为它没有存在的意义。且该参数不能从外部直接调用。 -
scala自动提供的setter 和 getter不符合标准的java bean规范
//`java bean`:
public String getName(){ }
public void SetName(String name){ }
由于scala的生态不完善, scala大量的使用专门为java准备的那些类库。这些类库在底层一般要用到标准的java的getter和setter,所以如果要用到java的类库,需要添加标准的java的getter和setter。
- 使用注解添加标准
bean
class User2(@BeanProperty var name: String, @BeanProperty val age: Int, @BeanProperty sex: String)
// 使用 @beanproperty 进行注解后,仍然保留原来 scala 的 getter 和 setter。
// @beanproperty 不止可以注解主构造器中的变量,类体中的变量依然可以进行标注。
6.2.4 构造器重载
scala也支持构造器的重载。
整体分两种构造器:
-
主构造器:紧跟着类名。
-
辅助构造器:和主构造构成了重载关系,功能相对较弱。
// 定义一个无参辅助构造器 def this() = { // 注意: 首行必须是调用自己的主构造器 this("lisi") } def this(age: Int) = { this("lisi") this.age = age } // 注意:只有辅助构造器中才能使用 this.para = para 进行初始化,主构造器中只能上文中的方式进行初始化。 def this(a: Int) = { this() }注意:
- 后定义的辅助构造器只能调用先定义的辅助构造器或主构造器。
- 辅助构造函数的参数仅仅是一个普通的参数,不会成为类的属性,除非在构造函数中进行了显式的赋值。
6.3 包
包的概念和java的是一样的,包的作用如下:
- 区别类名相同类
- 方便对类进行管理
- 控制访问范围
6.3.1 包的声明
-
支持和
java一样的声明方式(基本这种使用)package com.jeffery.scala1128.day04.pack -
支持多个
package语句(很少碰到)package com.jeffery.scala1128.day04.pack package a.b // 等同于 package com.jeffery.scala1128.day04.pack.a.b -
包语句(很少碰到)
package c{ // c其实是子包 class A }
6.3.2 包的导入
-
导入和
java一样,在文件最顶层导入,整个文件的任何位置都可以使用。import java.util.HashMap -
在
scala中其实在代码任何位置都可以导入。(掌握)def main(args: Array[String]): Unit = { import java.io.FileInputStream // 只能在main函数中使用 val is = new FileInputStream("c:/users.json") } -
导入类的时候,防止和现有的冲突,可以给类起别名
import java.io.{FileInputStream => JFI} -
如何批量导入(掌握)
import java.io._ // 导入java.io包下所有的类 (java是*) -
屏蔽某个类
import java.io.{FileInputStream => _, _} //屏蔽 FileInputStream -
java中有静态导入// 只能导入静态成员 import static 包名;// scala 只需导入包名即可 import java.lang.Math._ -
scala还支持导入对象的成员(掌握)val u = new User // 把对象u的成员导入,可以直接调用其方法 import u._ foo() eat()
6.3.3 公共方法的处理
java中一般使用工具类,在工具类中写静态方法。因为java中所有的方法都需要依附于类或者对象。scala中为了解决这个问题, 提供了一个包对象。在这个包内使用包对内的方法的时候,直接调用即可。
package com.jeffery.scala1128.day04
package object pack {
def foo1() = {
println("foo...")
}
def eat1() = {
println("eat...")
}
}
之后在com.jeffery.scala1128.day04.pack包下所有的类中都可以直接调用这些方法;但在子包中调用时则需要导入包对象。
6.3.4 默认导入
有3个默认导入
java.lang._scala._scala.Predef._
6.4 继承
继承和java一样,是扩展类的一种方式。面向对象的3大特征:
-
封装
-
继承(单继承)
-
多态:有了继承自然就有多态
6.4.1 继承的基本语法
class A
class B extends A
6.4.2 方法的覆写
6.4.2.1 java 中方法的覆写规则
两同:方法名、参数列表
两小: 返回值类型 —— 子类的返回值类型应该等于或小于父类的返回值类型
抛的异常 —— 子类的方法抛的异常要小于父类抛的异常
一大:访问权限 —— 子类要大于父类访问权限
scala 中遵守同样的规则
6.4.2.2 不同点
在java中Override注解 (1.6加入) 是可选的;在scala中, override是一个关键字,且必须添加。
6.4.3 多态
定义:如果一个对象的编译时类型和运行时类型不一致,就说明发生了多态。
-
编译时类型:
=左边是编译时类型。 编译的时候是否可以通过要看编译时类型。
-
运行时类型:
创建对象时使用的类型就是运行时类型。
运行时方法的具体表现要看运行时类型。
注意:在
java中, 属性没有多态,方法才有多态。
属性覆写(scala独有)
在
scala中,属性也可以覆写,也具有多态。属性覆写的规则:
val 只能覆写 val 和没有形参的 def。
var 只能覆写抽象 var 和 抽象字段(其实是一回事)。
注意:
- var 是不能覆写的,因为 var 在继承后可以重新赋值,没有覆写的必要;而覆写 val 是因为 val 是 final 常量 ,想改变其值只能通过覆写。
- val 覆写的实质就是在子类中对其重新赋值,其他不做变化。由于 val 的实质是一个 get 方法,因此调用子类的 get 方法时会返回子类中重新赋值后的 val。
6.4 继承的时候构造的处理
- 在子类的辅构造器中,必须先调用自己的主构造,不能主动去调用父类的构造器。
- 只有主构造器才有权利去调用父类的构造器。
class S(override val age: Int) extends F(age) {
println("S 主构造内的代码 1")
println("S 主构造内的代码 2")
override def foo(): Unit = {
super.foo()
println("S foo...")
}
}
6.5 抽象类
java中的抽象类:
- 用
abstract修饰类就是抽象类。 - 抽象类中可以有普通类有的所有成员。
- 抽象类还可以有抽象方法。
- 抽象类不能直接创建对象,必须创建子类的对象。
scala中抽象类定义和特点与java一样
abstract class A{
def foo()= {
println("foo...")
}
// 只有签名, 没有实现
def eat(): Unit
}
注意:
// 抽象字段, 或抽象属性.
// 抽象属性包含 var 和 val
var age: Int
val sex: String
总结:
- 相比
java多了抽象字段的概念
6.6 权限修饰符
6.6.1 java的权限修饰符
-
用在外部上
-
public-
所有地方都可以找到这个类
-
这个类的类名要文件名保持一致(
.java)
-
-
默认
-
-
用在类的内部成员 (属性, 方法, 内部类) 上
四种修饰符
-
public所有地方都可以访问
-
protected同包和子父类中可以访问
在子类中访问
protected的方法的时候,使用以下语句进行中访问:super.foo(); -
默认(
friendly)同包中访问
-
private只能在当前类中访问
-
6.6.2 scala 的权限修饰符
-
用在外部类上:
-
默认(
public, 没有public关键字) -
private只能在当前包使用,其他地方无法使用
-
-
用在类的内部成员(属性, 方法, 内部类)上
-
默认(
public, 没有public关键字) -
protected这个限制更加严格,只能在子父类中访问,即使在同包中也不能访问。
super.foo(); -
private只能在当前类中访问。
scala中做了一些改造,可以精细化控制。private[mode] def speak() = println("speak...")在
mode包和它的子包中可以访问。
-
6.7 单例对象
// 孤立对象天生就是单例的
object 对象名{
// 也可以写代码
def main(args: Array[String]){
// 入口
}
}
注意:孤立对象的地位等同于 java 中的静态,其本质是实例化后的对象,因此不能自定义构造器。
6.8 伴生类和伴生对象
object User{
// 也可以写代码
def main(args: Array[String]){
// 入口
}
}
class User private (val age: Int){
// 使用 private 将构造器私有化后只有它的伴生对象可以访问。
}
class的名字和object的名字相同,就是伴生类和伴生对象。- 他们可以互相访问对方的私有成员。(因为它们编译成字节码文件之后都在一个类中)
- 伴生类和伴生对象必须在同一个
.scala文件中。 - 将来编译成字节码之后,站在
java的角度,伴生对象中的成员都会成为静态成员,伴生类中的成员都会成为非静态成员。
// 补充
1. 伴生类中定义的字段和方法, 对应同名类中的成员字段和成员方法(非静态);
2. 伴生对象中定义的字段和方法, 对应同名类中的静态方法, 所以可以认为 Scala 中的 object关键字是静态的另一种表示方式, 只是 scala 将这些静态的东西也封装成了对象;
3. 伴生对象中定义的字段和方法, 对应虚构类中的成员字段和方法(除了一个虚构类的静态实例,其他都是非静态的);
4. 同名类中的静态方法, 会访问单例的虚构类对象, 将相关的逻辑调用到虚构类中的成员方法中。 由于虚构类是单例的, 所以可以保证伴生对象中的字段都是唯一的。 也就是说虚构类的单例性, 保证了伴生对象(即scala中的object修饰的单例对象)中信息的唯一性。
案例:女娲造人
object Human {
def main(args: Array[String]): Unit = {
println(makeHuman("黄"))
println(makeHuman("白"))
println(makeHuman("黑"))
println(Human.getClass.getSimpleName)
}
private val humans: mutable.Map[String, Human] = mutable.Map[String, Human](
"黄" -> new Human("黄"),
"黑" -> new Human("黑"),
"白" -> new Human("白")
)
def makeHuman(color: String) = humans.getOrElseUpdate(color, new Human(color))
}
class Human private (val color: String){
println(s"造 $color 种人")
override def toString: String = s"$color 种人"
def eat = println("eating...")
}
补充:伴生对象还可以继承伴生类,下面这种写法实际上是创建伴生类的一个实例,同样且可以调用伴生类的私有构造器。
object ObjDemo {
def main(args: Array[String]): Unit = {
println(Student.name)
println(Student.age)
Student.foo
}
}
class Student private(val name: String, val age: Int){
def foo = println("foo .....")
}
object Student extends Student("zhangsan", 25)
6.9 apply
函数的特点是可以调用。在scala中,任何对象都可以像函数一样去调用执行。
// 函数调用:
函数名(参数) // 函数名.apply(参数),方法需转为 (方法名 _).apply(参数)
// 对象调用
对象名(参数) // 等价于去调用对象的 apply 方法
注意:
- 其实函数也可以通过 apply 进行调用(方法需要先转成函数再使用)。
- 伴生对象的
apply通常情况是返回伴生类的实例,这样在创建对象的时候, 可以省略new。 - 普通类中的
apply一般根据具体的业务逻辑来实现,仅供其实例化对象调用。 apply支持重载。
案例:
// 实现自定义的 MyArray
object ApplyTest2 {
def main(args: Array[String]): Unit = {
val array = MyArray(1, 2, 3)
println(array(2))
}
}
// 孤立对象中定义的 apply 仅供类调用
object MyArray{
def apply(args: Int*): MyArray = new MyArray(args: _*)
}
// 类中定义的 apply 仅供实例化对象调用
class MyArray(val args: Int *){
def apply(index: Int): Int = args(index)
}
6.10 trait
6.10.1 基本介绍
特质(trait):由于java中接口不够面向面向对象,scala 在其中加入了trait (特质)。
-
实现接口 = 混入特质。
-
接口支持多实现,特质支持多混入。
-
特质编译为字节码文件之后,依然还是接口;若实现了部分的字段或方法,那么除了接口之外还有一个名为
trait名$class的抽象类。
6.10.2 trait 包含成员
抽象类能有的成员特质都可以有。
- 属性
- 方法
- 抽象属性
- 抽象方法
- 构造器(主/辅)
java接口:
- java 1.8之前是抽象方法和常量的集合
- 从 java 1.8 开始有默认方法
6.10.3 trait 和抽象类的区别
trait可以多混入,抽象类只能单继承。
混入多个 trait 的操作如下:
class A extends t1 with t2 with t3...
// 继承类和混入 trait 同时出现在语句中时,需先继承类,后混入 trait
6.10.4 使用细节
-
JVM 先加载 trait 后加载实现后的类,且加载多个 trait 时按照自左向右的顺序进行加载。
-
抽象属性在实现之前都是各个类型的默认值。
-
只包含抽象方法和抽象字段的 trait 反编译后:接口。
-
包含抽象成分和部分实现成分的 trait 反编译后:接口 + 抽象实现类。
-
若抽象方法返回的是 Unit,则返回值类型和:都可以省略(省略不代表没有)。
-
只能单继承类,且类要放在特质前边。
-
trait 只能有一个默认的无参构造器。
6.10.5 叠加冲突
多个trait有同名同返回值的抽象方法时,不会产生冲突,实现即可调用。
多个trait有同名实现好的方法时,会产生冲突。
多个trait有同名不同返回值的方法时,会产生冲突。
-
解决方案 1
在子类中把冲突的方法覆写一下,这样在调用时会无视 trait 中定义的同名方法,直接调用子类中覆写后的同名方法。
-
解决方案 2
(1)给造成冲突的父 trait 再创建一个更高一级的 trait。
(2)冲突的方法最终使用的是最后加载的那个(编译器自动实现)。
- 初始化时,一个
trait最多初始化一次。 - 初始化按照从左向右的顺序进行,有父 trait 的先加载父 trait。
super.foo()不是真正的找父类,而是按照叠加的顺序向前找。super[T12].foo()明确指定这个super应该是哪个类。
- 初始化时,一个
// 示例
object trait3 {
def main(args: Array[String]): Unit = {
new C12()
}
}
trait T12{
println("加载 T12")
def foo = println("T12 foo ...")
}
trait T1 extends T12{
println("加载 T1")
override def foo: Unit = println("T1 foo ...")
}
trait T2 extends T12{
println("加载 T2")
override def foo: Unit = {
super[T12].foo
println("T2 foo ...")
}
}
class C12 extends T1 with T2 {
println("加载 C12")
foo
}
6.10.6 特质继承类
-
方法 1:显式地使用继承语句
extendsclass A{ def foo() = { println("A... foo") } } trait B extends A{ def eat() = { println("B ... eat") foo() } } // extends 要么是 A,要么 A 的子类,否则将破坏 scala 的单继承原则 class C extends A with B -
方法 2:使用自身类型 (
selftype)trait B{ // s就是A类型的对象 s: A => def eat()= { println("B ... eat") s.foo() } } // 或使用以下操作 trait B { _: A => def eat() = { println("B ... eat") this.foo() } }
补充:反编译后的字节码文件中,实际上是在特质对应的抽象类中调用了被继承类的方法。
6.10.7 动态叠加
在java中所有的继承关系都应该在定义类时确定好;
而scala支持特质的动态叠加。在创建对象的时候,可以临时只针对整个对象来叠加特质。
object Trait5 {
def main(args: Array[String]): Unit = {
val h = new H with F1
h.foo()
}
}
class H
trait F1 {
// 若 F1 中含有抽象方法,还需要将抽象方法实现,类似于匿名内部类的用法
def foo() = println("f1 foo...")
}
6.11 知识拓展
- 类型的判断和强转
object Extra1 {
def main(args: Array[String]): Unit = {
val a:A = new B
// java中判断类型: a instanceof B (通过关键字来进行判断)
if (a.isInstanceOf[B]) { // 判断a是否为B的对象
val b = a.asInstanceOf[B] // a转换B的类型
b.foo()
}
// java 中的强转:(B)a
val c = 10.5
if (c.isInstanceOf[Double]) println(c)
println(c.asInstanceOf[Int])
}
}
class A
class B extends A{
def foo() = println("foo...")
}
-
枚举类
特点:有个类型,它的对象是预先创建好的有限个对象。
-
使用
java的来定义 -
scala自己模拟枚举类object EnumDemo1 { def main(args: Array[String]): Unit = { val spring: Season = Spring println(spring.getClass.getName) } } // sealed 表示密封类,禁止外部继承或实现该类 // object 孤立对象天生具有单例的特性 sealed abstract class Season object Spring extends Season object Summer extends Season object Autumn extends Season object Winter extends Season -
使用
scala提供的 Enumeration 类来完成object EnumDemo2 { def main(args: Array[String]): Unit = { println(WeekDay.Mon.getClass.getName) } } object WeekDay extends Enumeration{ type WeekDay = Value val Mon, Tue, Wed, Thu, Fri, Sat, Sun = Value }
-
-
scala中的内部类类型投影
object InnerDemo { def main(args: Array[String]): Unit = { val outer1 = new Outer val inner1 = new outer1.Inner val outer2 = new Outer val inner2 = new outer2.Inner inner1.foo(inner1) inner2.foo(inner1) } } class Outer { //自身类型 that => println("loading outer class ...") val a = 20 val b = 30 class Inner { println("loading inner class ...") val a = 200 // 外部类和内部类中包含同名变量时,默认输出内部类中的变量 // 类型投影 def foo(obj: Outer#Inner): Unit ={ // 输出内部类变量 println("1-----" + this.a) println("2-----" + a) // 输出外部类变量 println("3-----" + Outer.this.a) println("4-----" + that.a) } } } -
继承 App 可以直接调用 main 方法(spark 中禁用)
object AppDemo extends App {
// 在 spark 不要用。如果使用, 结果可能会出错.
println("xxxx")
val a = 100
println(a)
}
// 验证:使用 println(Thread.currentThread().getName) 可以看到是在 main 线程里
- Type 定义(类似于 C 中的宏定义)
object TypeDemo {
def main(args: Array[String]): Unit = {
type a = TypeDemoStudentPersonAnimal
val a = new a
a.foo
// 输出的类名依然为原来的类名
println(a.getClass.getSimpleName)
}
}
class TypeDemoStudentPersonAnimal{
def foo = println("-----------------")
}
第七章 隐式转换
隐式转换是scala一个高级特性,也是scala源码较难理解的地方。
- 隐式转换函数。
- 隐式类(其实对隐式转换函数一种简化),出现得比较晚 (
2.1.X版本后出现)。 - 隐式参数和隐式值。
7.1 隐式转换函数
- 情景1:赋值时的类型转换
// 在作用域内只能有一个, 如果有多个 Double=> Int 那么这个时候, 隐式转换就可能不会发生
// 方法体和类体内同时出现且一样时,就近原则
// 方法体和类体内同时出现且不一样时,不能进行转换
implicit def double2Int(d: Double): Int = d.toInt
val a: Int = 10.1 // Double=> Int
- 情景2::对已有的类做功能扩展(调用已有类不存在的新方法)
object ImplicitDemo2 {
def main(args: Array[String]): Unit = {
// 读取文本文件中的内容 java: IO
implicit def file2RichFile(file: File) = new RichFile(file)
val content = new File("C:\\Users\\lzc\\Desktop\\class_code\\2019_11_28\\01_scala\\scala1128\\src\\main\\scala\\com\\jeffery\\scala1128\\day06\\implicitdemo\\ImplicitDemo2.scala").readContent
println(content)
}
}
class RichFile(file: File) {
// 这个方法要真正的去封装读 文件 内容的代码
def readContent: String = {
// Array(1,2,3,4) => arr.mkString "1234"
// Array(1,2,3,4) => arr.mkString(",") "1,2,3,4"
Source.fromFile(file, "utf-8").mkString
}
}
总结
-
什么时候会用到隐式转换?
-
把
A类型的值赋值给B类型的时候,A和B没有任何的关系。这个时候会去找一个隐式转换(A => B)。如果有,则编译成功,自动把 A 转成 B,且赋值给 B。val a: A = new A val b:B = a // 会找隐式转换 -
在调用一个对象
a的方法(foo)的时候,如果这个对象a没有这样的方法,那么会找一个隐式转换。这个隐式接受一个A类型的对象,返回一个新的对象,且新的对象中有foo,则转换成功。implicit def a(file:File) = new RichFile(file) val content = new File("..").readContent //RichFile中有一个readContent方法
-
-
隐式转换如何实现?
-
写一个隐式转换函数(隐式函数由系统自动调用)
- 函数名没有限制
- 参数一定是你原来的类型
- 返回值一定是你新定义的类型,例如:
implicit def a(file:File) = new RichFile(file)
-
写一个自定义的类(完成以前的类没有的功能)
-
自定义一个类:主构造接受已有的类型
-
在定义一个你需要的方法
class RichFile(file: File){ def readContent = {} }
-
-
7.2 隐式类
用implicit修饰的类就是隐式类。
- 省略去写隐式转换函数。
- 隐式类可以看成是隐式转换函数的升级版。
- 隐式类不能是顶级类,只能是内部类(成员内部类、局部内部类均可)。(因为
implicit不能修饰顶级元素) - 隐式类反编译后为内部类。
隐式类实现方式:
- 在隐式转换函数的基础上,去掉隐式转换函数 “implicit” 后的内容。
- 将自定义类放置到 “implicit” 后方。
implicit class RichFile(file: File) {
// 这个方法要真正的去封装读 文件 内容的代码
def : String = {
// Array(1,2,3,4) => arr.mkString "1234"
// Array(1,2,3,4) => arr.mkString(",") "1,2,3,4"
Source.fromFile(file, "utf-8").mkString
}
}
2.3 隐式参数和隐式值
隐式参数和隐式值要配合使用。
implicit val aaa: Int = 100
def main(args: Array[String]): Unit = {
foo
}
// a 是隐式参数, 将来调用的时候根据需要,可以不传
// 让 scala 自动帮助我们传递, 找一个隐式值
def foo(implicit a: Int) = {
println(a)
}
注意
-
找隐式值的时候只看类型,不看变量的名字。
-
在作用域内只能有一个同类型的隐式值。
-
一个隐式参数列表内如果有多个参数,则这些参数都是隐式的。
-
如果一个函数有很多参数,有些用是隐式参数,有些不是,怎么办? —— 对函数左柯里化
- 使用两个参数列表
-
第一个是必须要传的参数
- 第二个里面是隐式参数
-
如果使用隐式值, 则圆括号也要省略。
-
// 省略括号, 表示在使用隐式值 // 加上括号, 表示使用默认值
2.4 隐式转换函数、隐式类、隐式值的查找路径问题
- 先在当前作用域中查找。
- 之后去相关类型的伴生对象中查找。如果有泛型,泛型也是相关类型。(可以理解为该条语句中所有涉及到的类都会去搜索,而且只能有一个进行了 implicit 定义,否则就会报错)
// Predef 中会定义很多 implicit 函数和 implicit 类
例:String 可以调用 head 方法。原因是在 Predef 中先将 String 转换为 StringOps,之后再在 StringOps 中混入了 StringLike 特质,最终得以调用 head 方法。
// scala 源码
trait StringOrdering extends Ordering[String] {
def compare(x: String, y: String) = x.compareTo(y)
}
implicit object String extends StringOrdering
第八章 集合
8.1 概述
8.1.1 java 的集合框架
- 数组
List,Set,Map
8.1.2 scala 的集合框架
所有的集合框架有一些共同的方法。这方法虽然操作的集合不同,但是用法基本相同。另外提供了很多的高阶函数,用于操作集合中的元素。

- 不可变集合继承图

- 可变集合继承图

8.2 数组
8.2.1 定长数组 Array
底层其实本质就是java的数组:长度不能变,元素可以变换,打印数组名输出地址 hashcode。
创建数组
直接给元素初始化
val arr: Array[Int] = Array[Int](10, 20, 30)使用
new来创建new Array[Int](length)
几个集合通用的的运算符(可变集合、不可变集合都可以使用)
-
:+用来在集合的尾部添加元素,集合名写在运算符左边 -
+:用来在集合的头部添加元素,集合名写在运算符右边运算符的结合性:
a + b 左结合 a = 30 右结合 不成文规定: 如果一个运算符以 : 结尾,那么他就是右结合,即: 100 +: arr 等价于 arr.+:(100) -
++合并两个集合
object Array2 {
def main(args: Array[String]): Unit = {
val arr1: Array[Int] = Array(30, 50, 70, 60, 10, 20)
val arr2: Array[Int] = 100 +: arr1
val arr3: Array[Int] = arr1 :+ 100
val arr4: Array[Int] = 100 +: arr1 :+ 100
val arr5: Array[Int] = arr1 ++ arr1
myPrint(arr1)
myPrint(arr2)
myPrint(arr3)
myPrint(arr4)
myPrint(arr5)
}
def myPrint(array: Array[_]): Unit = println(array.mkString(", "))
}
8.2.2 可变数组 ArrayBuffer
创建可变数组
// 创建可变数组
val buffer = ArrayBuffer(10, 20, 30, 40, 10.3)
// 创建一个空的ArrayBuffer
new ArrayBuffer[Int]()
// 创建一个空的ArrayBuffer
ArrayBuffer[Int]()
+= 在可变集合的尾部增加元素(没有产生新的集合)
+=: 在可变集合的头部增加元素(没有产生新的集合)
buffer.append(1000) // java式的写法
buffer.prepend(2000)
buffer.insert(0, 200, 3000, 4000)
集合运算:
buffer1 ++= buffer2 // 把buffer2的内容之家到buffer1的内部 buffer1发生变化
buffer1 ++=: buffer2 // buffer1不变, buffer2发生了变化
8.2.3 扩展
其实定长数组也可以使用:+= 运算符,其本质是新建了一个长度为原长度 + 1 的数组,之后将新数组赋值给了原来的变量。
var arr1 = Array(30, 50, 70, 60, 10, 20)
// 等价于 arr1 = arr1 :+= 100
arr1 :+= 100
8.2.4 多维数组
和java完全一样,底层就是java的多维数组。本质都是假的多维数组,都是用一维数组模拟出来的。

案例:
object DimArray {
def main(args: Array[String]): Unit = {
// 二维数组的定义与赋值
val arr: Array[Array[Int]] = Array.ofDim[Int](3, 4)
arr(0)(3) = 100
// 二维数组的遍历
for (a <- arr){
for (ele <- a){
print(ele + "\t")
}
println()
}
for (a <- arr; ele <- a) print(ele + "\t")
}
}
8.3 List
8.3.1 不可变 List
// 1. 得到List集合
val list1 = List(10, 20, 30)
// val list2: List[Int] = list1 :+ 100
val list2: List[Int] = 100 +: list1
// 专门用于不可变List的头部增加元素的运算符
val list2 = 100 :: list1
// val list3 = list1 ++ list2
val list3: List[Int] = list1 ::: list2 // list2.:::(lit1)
val list: List[Int] = 10 :: 20 :: 30 :: Nil // List(10,20,30,40)
:: 向List的头部添加元素 ( List 专用,等价于 +: )
::: 把两个List的元素合并到一起 ( List 专用,等价于 ++ )
Nil:空 List 集合
val list: List[Int] = 10 :: 20 :: 30 :: (Nil :+ 100)
println(list) // List(10, 20, 30, 100)
List 是 Seq 的默认实现,因此调用 Seq 即调用 List。
val seq = Seq(1, 2, 3, 4, 5)
println(seq.isInstanceOf[List[Int]]) // ture
println(seq) //List(1, 2, 3, 4, 5)
println(seq.asInstanceOf[List[Int]]) //List(1, 2, 3, 4, 5)
注意:scala 默认 Seq 是不可变的,若想用可变的 Seq,需加包名 mutable。
8.3.2 可变 List
// 可变 List 不能使用 :: 、:::
val buffer: ListBuffer[Int] = ListBuffer(10, 20, 30)
buffer += 100
100 +=: buffer
println(buffer)
8.4 元组
元组专门用来将那些数据类型不同的数据封装在一起,最多可以封装 22 个数据对象。
8.4.1 创建元组 (tupple)
object Tuple1 {
def main(args: Array[String]): Unit = {
// 创建元组
val t1: (Int, Double, String, Boolean) = Tuple4(1, 2.2, "dfdf", false)
println(t1._1)
println(t1._2)
println(t1._3)
println(t1._4)
val t2: (Char, Int) = ('a', 10) // 等价于 Tuple2("a", 10)
val t3: (String, Int) = "a" -> 97 // 此种赋值方式同样使适用
val iterator: Iterator[Any] = t2.productIterator
for (ele <- iterator) println(ele)
}
}
- 元组不可变,不能修改(只读)。
- 元组不能直接遍历,其实没有这样的需求。
- 元组可以嵌套。
// 选择赋值(对号入座)
val (a, _) = (10, 5)
println(a)
8.5 Set
8.5.1 Set 特点
-
无序不重复
有序:
取出顺序和放入顺序一致叫做有序。
无序:
遍历顺序和放入顺序不一致叫做无序。
注意:
TreeSet可以实现自动排序,但并不是有序集合 -
去重
List、Array 集合转成 Set 之后会自动去重。
-
Set 同样有可变 Set 和不可变 Set 两种,默认为不可变的 HashSet。
注意:scala 默认 Set 是不可变的,若想用可变的 Set,需加包名 mutable。
8.5.2 集合运算
- 支持元素加减运算
object SetDemo1 {
def main(args: Array[String]): Unit = {
val set1 = Set(1, 2, 3, 4, 5, 6)
val set2 = set1 + 10
val set3 = set1 - 5
println(set1)
println(set2)
println(set3)
}
}
// 可变 Set 同样支持 += 、-= 赋值运算,此处不再进行详述
- 支持集合布尔运算
val set1 = Set(10,20,30,50)
val set2 = Set(1,20,30,5)
// 并集
println(set1 ++ set2) // ++ 所有集合通用
println(set1 | set2) // Set 集合独有
println(set1.union(set2))
// 交集
println(set1.intersect(set2)) // java
println(set1 & set2) // Set 集合独有
// 差集
println(set1 &~ set2) // Set 集合独有
println(set1 -- set2)
println(set1.diff(set2))
- 补充
在scala中,几乎所有的集合之间都可以互相转换。
list.toSet
set.toList
set.toArray
set.toBuffer
8.6 Map
8.6.1 Map 简介
Map同样分可变和不可变。- 存储的是键值对,键值对中的键不能重复。
- 在
scala中使用元组来表示键值对。 - Map 的遍历结果是元组。
- 通常使用 map(key) 获取元素的值。
- 获取元素最好使用
map.getOrElse(key, defaultVlaue)。 - 可变
Map多了一个map.getOrElseUpdate(key, defaultVlaue)运算,用于更新 map 集合。 - 支持将 key 以 Set 的形式返回:
.keySet。
注意:
// map 添加元素只能用 += a -> b 或 put
map.put("password", pwd)
map += "dbtable" -> "user"
8.7 集合常规操作
8.7.1 常规操作一
object BasicOperation {
def main(args: Array[String]): Unit = {
val list1 = List(30, 50, 70, 60, 10, 20)
// (1)获取集合长度
println(list1.length)
// (2)获取集合大小
println(list1.size)
// (3)循环遍历
list1.foreach(println)
// (4)迭代器
println("----------")
val it: Iterator[Int] = list1.iterator // 注意:一个迭代器只能使用一次
println(it.hasNext)
println(it.isEmpty)
while (it.hasNext) {
println(it.next()) // 返回刚刚跳过的那个元素
}
// (5)生成字符串
println(list1.mkString("-> "))
// (6)是否包含
println(list1.contains(30))
}
}
8.7.2 常规操作二
object PrimaryOperation {
def main(args: Array[String]): Unit = {
val list1 = List(30, 50, 70, 60, 10, 20)
// (1)求和
println(list1.sum)
// (2)求乘积
println(list1.product)
// (3)最大值
println(list1.max)
// (4)最小值
println(list1.min)
}
}
8.7.3 常规操作三
object SubCollections {
def main(args: Array[String]): Unit = {
val list1 = List(30, 50, 70, 60, "abc")
val list2 = List("30", "50", "7", "6", "10", "2", "abc")
// (1)获取集合的头head
println(list1.head)
// (2)获取集合的尾(不是头就是尾)tail
println(list1.tail)
// (3)集合最后一个数据 last
println(list1.last)
// (4)集合初始数据(不包含最后一个)
println(list1.init)
// (5)反转
println(list1.reverse)
// (6)取前(后)n个元素, 注意并非取 index, 而是元素数量
println(list1.take(3))
println(list1.take(30))
println(list1.takeRight(2))
// (7)去掉前(后)n个元素
println(list1.drop(2))
println(list1.dropRight(3))
// (8)并集
println(list1.union(list2))
// (9)交集
println(list1.intersect(list2))
// (10)差集
println(list1.diff(list2))
// (11)拉链
// val list3: List[(Int, Int)] = list1.zip(list2) // 多出会忽略
// val list3 = list1.zipAll(list2, -1, "fff") // 配置默认值
val list3 = list1.zipWithIndex // 元素和索引进行拉链
println(list3)
// (12)滑窗,第二个参数默认为 1
val it: Iterator[List[String]] = list2.sliding(3, 1)
println(it.toList)
println(list1.sliding(3, 1).toList)
}
}
注意:一个迭代器只能使用一次。
8.8 集合高级操作
集合提供的一些高阶函数(高阶算子)
-
foreach遍历集合,只进不出。对集合中的每个元素进行相同的操作,用法与自定义的 foreach 一致,常用于遍历打印。
-
map遍历集合,一进一出。原来有
n个元素,那么经过map之后,一定也是n个元素。用于对集合进行数据结构的调整。用法与自定义的 map 一致。
foreach, map-
共同点:
都会遍历集合中的元素。
-
不同点:
foreach仅仅是遍历map会有返回值。
-
-
filter过滤器,一进一出或零出。满足要求的留下来,不可满足的去掉。用法与自定义的 filter 一致。
-
flatten拍平。如果一个集合中存储的是集合,才可以使用
flatten。字符串是 char 的数组,因此也可以使用 flatten。 -
groupBygroupBy(x => x._1) // 传入变量 x(元组),按照 x 的第一个分量进行分组 groupBy(x => if (x % 2 == 0) "偶数" else "奇数") // 按照 x 奇数偶数进行分组 -
flatMapmap 和 flatten的合体。按照 先 map 后 flatten 的顺序执行。总结
map一进一出filter一进0出或1出flatMap一进多 (0, 1 , >1) 出
-
WordCount(1)java 式写法:核心逻辑是使用 foreach 操作 List 集合中的每一个元素。
val list = List("hello", "world", "hello", "jeffery", "hello", "jeffery") // 统计一下每个单词出现的次数 wordCount /* 分析: Map(hello->3, world->1, jeffery->2) */ var result = Map[String, Int]() list.foreach(x => { // x: hello result找到hello的个数, 把个数+1 result += x -> (result.getOrElse(x, 0) + 1) }) println(result)(2)scala 式写法
val list = List("hello", "world", "hello", "jeffery", "hello", "jeffery") // 如果匿名函数式原封不动的返回, 则不能化简 val wordCount = list .groupBy(x => x) .map(kv => (kv._1, kv._2.size)) println(wordCount)(3)读取文件并进行 WordCount
object WordCount3 { def main(args: Array[String]): Unit = { // 读取文件的内容, 统计文件中每个单词出现的次数 // 1. 读取文件 val buffer: BufferedSource = Source.fromFile("c:/1128.txt", "utf-8") // 2. 得到每行字符串 val lines: Iterator[String] = buffer.getLines() // 3. 把每行字符串切割成一个个的单词,切割后每行为一个 String 数组 // 使用 flatMap 将每个数组压平,并进行过滤 val words = lines .flatMap(_.split(" ")) .filter(_.trim.length > 0) // 过滤掉一些脏数据 // 4. 统计 // words.toList.groupBy(word => word) val wordCount = words.toList .groupBy(_.toString) .mapValues(_.size) println(wordCount) } } -
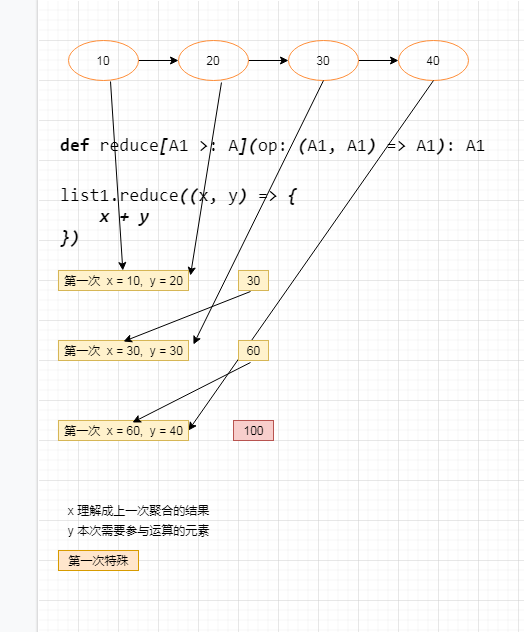
reduce聚合:最终的结果一定只有一个,使用方法与自定义的 reduce 一致。
-
foldLeft左折叠,最终结果的类型可以由
zero来决定。foldLeft 与 reduce 的区别:
- reduce 要求函数类型为
(A1, A1) => A1,即传入的两个参数和返回值必须一致。 - foldLeft 要求函数类型为
(B, A) => B,即返回值类型与第一个参数的类型必须一致。
reduce最终结果的类型和元素的类型是一致
- reduce 要求函数类型为
案例:
object FordLeft {
def main(args: Array[String]): Unit = {
val list1 = List(30, 50, 70, 60, 10, 20)
// 输出和
println(list1.foldLeft(0)(_ + _))
// 输出拼接后的字符串
println(list1.foldLeft("")(_ + _))
}
}
注: foldRight 调用了 foldLeft,在后者的基础上互换了一下参数的位置。
-
scan实为 foldLeft 的增强版,用法与 foldLeft 完全一致,不同的是 scan 会输出每一步执行结果。
8.8.1 UnionMap 案例
(1)foreach 实现
object UnionMap {
def main(args: Array[String]): Unit = {
val map1 = Map("a" -> 97, "b" -> 98)
val map2 = Map("b" -> 980, "c" -> 99)
// 将 map1 存入 result 作为临时结果
var result = map1
// 遍历 map2,对 result 中已有的 key 的 value 累加;
// result 中不存在的 key 的 value 新增
map2.foreach(kv => {
result += (kv._1 -> (result.getOrElse(kv._1, 0) + kv._2))
})
println(result)
}
}
(2)foldLeft 实现
object UnionMap2 {
def main(args: Array[String]): Unit = {
val map1 = Map("a" -> 97, "b" -> 98)
val map2 = Map("b" -> 980, "c" -> 99)
// 使用 foldLeft 遍历 map1,并传入 map2 作为 map 的初值
// 每轮迭代更新一次 map
//
val map3 = map1.foldLeft(map2)((map: Map[String, Int], kv: (String, Int)) => {
map + (kv._1 -> (map.getOrElse(kv._1, 0) + kv._2))
})
println(map3)
}
}
8.8.2 集合高级操作综合应用
- 编写一个函数,接收一个字符串,返回一个 Map,例如:
输入:indexes("Helloee")
返回: Map(H->List(0), e -> List(1, 5, 6), ...)
// 数字其实是下标
(1)解法1:foldLeft
def indexes(str: String) = {
str.zipWithIndex.groupBy(x => x._1)
.mapValues(_.foldLeft(List[Int]())((list, kv) => kv._2 :: list))
}
(2)解法2:
def indexes(str: String) = {
str.zipWithIndex.groupBy(x => x._1)
.mapValues(_.map(_._2).toList)
}
// 精髓:对集合中的元素再次使用 map 进行操作,即对嵌套式的集合进行嵌套式操作。
- 实现一个函数,作用与 mkString 相同,使用 foldLeft
object MymkString2 {
def main(args: Array[String]): Unit = {
val list1 = List(30, 50, 70, 60, 10, 20)
println(mymkString2(list1, "<<", "--", ">>"))
}
def mymkString2(list: List[Int], start: String, sep: String, end: String): String = {
list.foldLeft(start)((tmp, ele) =>
tmp + ele + sep
).dropRight(sep.size) + end
}
}
// 初步简化
def mymkString2(list: List[Int], start: String, sep: String, end: String): String = list.foldLeft(start)(_ + _ + sep).dropRight(sep.size) + end
// 进一步简化(foldLeft 等同于 /:)
def mymkString2(list: List[Int], start: String, sep: String, end: String): String = list./:(start)(_ + _ + sep).dropRight(sep.size) + end
// 极简版
def mymkString2(list: List[Int], start: String, sep: String, end: String): String = (start/:list)(_ + _ + sep).dropRight(sep.size) + end
- 实现 reverse 函数的功能
object MyReverse {
def main(args: Array[String]): Unit = {
val str = "123456"
println(myReverse(str))
val list1 = List(30, 50, 70, 60, 10, 20)
println(myReverse(list1))
}
// 反转数组
def myReverse(str: String): String = {
str.foldLeft("")((x, y) => y + x)
}
// 反转 list(使用 folder)
def myReverse(list: List[Int]): List[Int] = {
list.foldLeft(List[Int]())((tmp, ele) => ele :: tmp)
}
// 反转 list(递归法)
def myReverse2(list: List[Int]): List[Int] = {
if (list.isEmpty) Nil
else myReverse(list.tail) :+ list.head
}
}
8.9 排序
- 排序不涉及任何的具体排序算法(冒泡, 选择, 插入, 希尔, 快速, 归并)。
- 不管是对可变还是不可变,都不会修改原集合,都是返回一个新排好序的集合。
- Map 、Seq 、Set 中,只有 Seq 可以排序。
8.9.1 sorted 算子
java中的排序涉及到元素的大小比较
-
元素自己可以和其他的兄弟比较 1 < 2
让类实现
Comparable接口 -
找一个比较器进行比较两个元素大小
c.compare(a. b)优先级高Comparator-
compare(a, b)如果返回值小于零 a < b
返回值等于 a == b
返回值大于零 a > b
-
(1)排序方法1(类似于 java 中的自然排序,让 Bean 类具有比较功能)
实现 ordered 接口(compatible 接口的子 trait)中的 compare 方法后,即可调用 .sorted 方法进行排序。
object Sort1 {
def main(args: Array[String]): Unit = {
val list1 = List(new User3(20, "a"), new User3(10, "c"), new User3(15, "b"))
println(list1.sorted)
val u1 = new User3(20, "a")
val u2 = new User3(15, "a")
println(u1 > u2)
}
}
class User3(val age: Int, val name: String) extends Ordered[User3] {
override def toString: String = s"[age = $age, name = $name]"
override def compare(that: User3): Int = if (this.age > that.age) 1 else if (this.age == that.age) 0 else -1
}
(2)排序方法2(类似于 java 中的定制排序,使用自定义的比较器进行比较)
自定义比较器实现 ordering trait 中的 compare 方法,创建匿名内部类的实例。之后将创建好的实例传递给.sorted(Ordering) 或将创建好的实例声明为隐式参数。调用.sorted 方法进行排序。
object Sort2 {
def main(args: Array[String]): Unit = {
implicit val odr = new Ordering[User4]{
override def compare(x: User4, y: User4): Int = if (x.age > y.age) -1 else if (x.age == y.age) 0 else 1
}
val list1 = List(new User4(20, "a"), new User4(10, "c"), new User4(15, "b"))
println(list1.sorted)
}
}
class User4(val age: Int, val name: String) {
override def toString: String = s"[age = $age, name = $name]"
}
8.9.2 sortBy 算子(简单易用,应用得最多)
sortBy[B](f: A => B)
// 接受一个匿名函数,A 为待排序数据类型,B 为可排序的数据类型。即将待排序数据类型换算为可排序数据类型后进行排序。
// 案例
object Sort3 {
def main(args: Array[String]): Unit = {
val list1 = List(30, 50, 70, 60, 10, 20)
// 倒序
println(list1.sortBy(x => -x))
println(list1.sortBy(x => x)(Ordering.Int.reverse))
// 按照字符串的长度倒序排序
val list2= List("abc", "a", "c", "dd", "aaa")
println(list2.sortBy(x => x.length)(Ordering.Int.reverse))
// 按照长度排升序排, 长度相等则按照字母表的升序排
println(list2.sortBy(x => (x.length, x)))
// 按照长度排降序排, 长度相等则按照字母表的升序排
// 最大支持 Ordering.Tuple9,再大就需要自己写
println(list2.sortBy(x => (x.length, x))(Ordering.Tuple2(Ordering.Int.reverse, Ordering.String)))
// 对自定义类进行排序
val list3 = List(new User4(20, "a"), new User4(10, "c"), new User4(15, "b"))
println(list3.sortBy(user => (-user.age, user.name)))
}
}
// 补充:minBy(_.ts) 等价于 sortBy(_.ts).head
8.9.3 sortWith
sortWith(lt: (A, A) => Boolean)
// 传入一个返回值为 Boolean 的匿名函数,返回值为 true 时将第一个参数排在前面,例如:
// x 是否小于 y —— 如果返回true, 表示 x < y,x 在前 y 在后。
val list2 = list1.sortWith((x, y) => {
x > y
})
8.9.4 高级 WordCount
// 统计单词的数量, 然后再按照单词的数量进行降序排列
object WorldCount {
def main(args: Array[String]): Unit = {
val tupleList: List[(String, Int)] =
List(("Hello Scala Spark World", 4), ("Hello Scala Spark", 3), ("Hello Scala", 2), ("Hello", 1))
println(foo1(tupleList))
println(foo2(tupleList))
}
def foo2(list: List[(String, Int)]) = {
list.flatMap(kv => kv._1.split(" ").map(x => x -> kv._2))
.groupBy(x => x._1)
.mapValues(list => list.foldLeft(0)((tmp, ele) => tmp + ele._2))
.toList
.sortBy(-_._2)
}
def foo1(list: List[(String, Int)]): List[(String, Int)] = {
list.map(kv => (kv._1 + " ") * kv._2)
.flatMap(_.split(" "))
.groupBy(x => x)
.mapValues(_.size)
.toList
.sortBy(-_._2)
}
// Map Seq Set 中,只有Seq可以排序
}
注意:要清楚每一步的输入和输出。
8.10 其他集合介绍
8.10.1 栈(stack)
object StackDemo {
def main(args: Array[String]): Unit = {
val stack: mutable.Stack[Int] = mutable.Stack(10, 20, 30)
stack.push(40)
println(stack)
stack.pop()
println(stack)
}
}
8.10.2 队列(queue)
object QueueDemo {
def main(args: Array[String]): Unit = {
val queue: mutable.Queue[Int] = mutable.Queue(10, 20, 30, 40)
queue.enqueue(50, 60)
println(queue)
queue.dequeue()
println(queue)
}
}
8.10.3 并行集合(集群中极少使用)
object ParDemo {
def main(args: Array[String]): Unit = {
val list1 = List(30, 50, 70, 60, 10, 20).par
list1.foreach(x => {
println(x + " " + Thread.currentThread().getName)
})
}
}
8.10.4 Option
Option 抽象类只有两个实现类:Some 和 None。
常用方法:① isEmpty ② isDefined ③ get
object OptionDemo {
def main(args: Array[String]): Unit = {
val opt1: Option[Int] = Some(10)
println(opt1.isEmpty)
if (opt1.isDefined) {
println(opt1.get)
}
val opt2: Option[User4] = foo()
opt2.foreach(println)
}
def foo(): Option[User4] = {
Some(new User4(10, "jack"))
}
}
补充:
- Option 集合同样支持 flatten 方法,Some 经过 flatten 后为 get 后的值,None 经过 flatten 后消失。
- Option 元素同样支持 getOrElse(value) 方法,对 Some 效果等同于 get 方法,对 None 则返回 value 的值。
8.10.5 Either
Option 抽象类只有两个实现类:Left 和 Right。
常用方法:① isLeft ② isRight ③ get
object EitherDemo2 {
def main(args: Array[String]): Unit = {
val e: Either[Int, String] = Right("对")
if (e.isLeft) {
println(e.left.get)
}else{
println(e.right.get)
}
}
}
8.10.6 惰性求值
- 基本介绍
object LazyDemo {
def main(args: Array[String]): Unit = {
val list1 = List(30, 50, 70, 60, 10, 20)
val stream: Stream[Int] = list1.toStream
println(stream) // 默认只求取第一个
println(stream.head)
println(stream.tail.head)
println(stream.tail)
println(stream) // 求取过一次之后就有值了
println(stream.take(3))
println(stream.take(3).force) // force 可以强制求值
}
}
// Stream 和 View 都是惰性求值数据结构,区别是 Stream 求取过一次之后就有值了,而 View 每次都要重新求取。
- 应用案例
(1)递归法求常值 List
object LazyDemo {
def main(args: Array[String]): Unit = {
val s: Stream[Int] = getS
println(s)
println(s.take(20).force)
}
// Stream 惰性求值不会出现死归,因为只会求取第一个值
def getS: Stream[Int] = {
1 #:: getS
}
}
// 用类似的思路求 List 集合
object LazyDemo {
def main(args: Array[String]): Unit = {
val s: List[Int] = getList(10)
println(s.take(20))
}
def getList(n: Int): List[Int] = {
if (n <= 0) Nil
else n :: getList(n-1)
}
}
(2)求斐波那契数列
object LazyDemo {
def main(args: Array[String]): Unit = {
println(fibSeq(6))
}
// 计算前多少项
def fibSeq(n: Int): List[Int] = {
// 方法一
def go(a: Int, b:Int): Stream[Int] = {
a #:: go(b, a + b)
}
go(1, 1).take(n).force.toList
// 方法二
def go: Stream[Int] = {
1 #:: go.scanLeft(1)(_ + _)
}
go.take(n).force.toList
}
}
8.11 集合小结
8.11.1 常用的集合
Array, List, Set, Map, Option
8.11.2 集合的基本操作
遍历、取值、 head、tail等
8.11.3 高级操作
foreach
map 进行数据结构调整
flatMap 匿名函数的返回值必须是集合
filter 过滤. ETL
reduce 聚合(原理)
foldLeft 左折叠(聚合), 多了一个零值, 决定了最终的结果类型
groupBy 分组。之后一般需要 map 进行调整
sortBy 排序。传排序的指标; 定义 Ordering 比较元素大小
第九章 模式匹配
9.1 基本介绍
object Match1 {
def main(args: Array[String]): Unit = {
// 从键盘输入两个整数和一个运算符, 计算他们的运算结果
val a: Int = StdIn.readInt()
val b: Int = StdIn.readInt()
val operation: String = StdIn.readLine() // + - * /
operation match {
case "+" =>
println(a + b)
case "-" =>
println(a - b)
case "*" =>
println(a * b)
case "/" =>
println(a / b)
// 匹配所有
case _ =>
println("你的运算符有问题...")
}
}
}
- 模式匹配是对
java中的switch的升级,其功能远远大于switch。 - 模式匹配的时候如果匹配不到会抛异常。
- 因此最后一般需要一种情形来匹配所有。
case aa =>
// 可以使用匹配到值
case _ =>
// 匹配到的值用不了(相当于 Linux 中的黑洞)
// 本质是一样的(匹配所有传入的变量)
- 关于匹配常量还是变量
// 通过字母大小写来进行区分
// case 后面首字母是大写表示常量,首字母是小写表示变量
case Baaaa => // Baaaa是常量
case baaaa => // baaaa新定义的变量
- 任何的语法结构有值,模式匹配也有。模式匹配结构的值就是匹配成功的那个
case的最后一行代码的值,类型是所有 case 返回类型的公共父类。
9.2 匹配类型
匹配的同时可以实现转换。
-
匹配类型 (简单)
object MatchDemo2 { def main(args: Array[String]): Unit = { // val a: Any = 100 val a: Any = 99 a match { // 只匹配大于等于100的整数. 守卫 case a: Int if a >= 100 && a <= 110 => println(a to 110) case b: Boolean => println("是一个boolean: " + b) case _ => println("default") } } } -
匹配类型 (复杂)
object MatchDemo3 { def main(args: Array[String]): Unit = { val a: Array[Double] = Array[Double](1, 2, 3, 4, 5.5) val b: List[Double] = List[Double](1, 2, 3, 4, 5.5) val c = Map(1 -> 2,3 -> 4, 5 -> 6) // 数组可以匹配类型和泛型类型,因为其本质就是 java 的数组 a match { case a: Array[Double] => println(a.mkString(", ")) } // 对于 list 和 map,如果是带泛型的类型,泛型匹配不出来 b match { case b: List[_] => println(b) } c match { case c: Map[_, _] => c.foreach(println) } } } // 泛型擦除 // 泛型出现的目的, 是为了在写代码的时候类型更安全。 // 但是泛型只是出现在编译时, 编译成字节码之后, 泛型就不存在了。
9.3 匹配内容
本质是匹配对象。
// 匹配数组
object Match6 {
def main(args: Array[String]): Unit = {
val arr = Array(10, 20, 100, 200)
arr match {
// 直接匹配内容
case Array(a, b, c, d) =>
println(a)
println(d)
// 匹配部分内容
case Array(10, a, b, c) =>
println(a)
// 略过部分内容
case Array(10, a, _, 40) if a > 15 =>
println(a)
// _* 表示将剩余部分抛入“黑洞”
case Array(a, b, _*) =>
println(a)
println(b)
// rest@_* 表示将剩余部分赋值给 rest
case Array(a, b, rest@_*) =>
println(rest)
}
}
}
// 匹配 list
object ListMatch {
def main(args: Array[String]): Unit = {
//List匹配 内容
val list1 = List(30, 50, 70)
list1 match {
// 全部匹配
case List(a, b, c) =>
println(a)
// 匹配后将剩余内容赋值给 rest
case List(a, rest@_*) =>
println(rest)
// 中置运算符(与前者等价)
case head :: rest =>
println(head)
println(rest)
case _ :: two :: three :: Nil =>
println(three)
case a :: b :: c =>
println(c)
}
}
}
// 匹配 tuple
object TupleMatch {
def main(args: Array[String]): Unit = {
// 单个匹配
val t: Any = (10, 20)
t match {
case (a:String , b)=>
println(a)
println(b)
}
// 嵌套匹配
val t2: (Int, (Int, (Int, (Int, Int)))) = (1,(2,(3,(4,5))))
println(t2._2._2._2._2)
t2 match {
case (_,(_,(_,(_,a)))) =>
println(a)
}
// 遍历 map + 匹配 tuple
val map: Map[String, Int] = Map("a" -> 97, "b" -> 98)
map.foreach(kv => {
kv match {
case (k, v) => println(v)
}
})
}
}
案例练习
/*
编写一个函数,计算 List[Option[Int]] 中所有非None值之和。分别使用 match 和不使用 match 来计算
8. 我们可以用列表制作只在叶子节点存放值的树。举例来说,列表((3 8) 2 (5)) 描述的是如下这样一棵树:
*
/|\
* 2 *
/\ |
3 8 5
List[Any] = List(List(3, 8), 2, List(5))
不过,有些列表元素是数字,而另一些是列表。在Scala中,你必须使用List[Any]。
编写一个leafSum函数,计算所有叶子节点中的元素之和.
*/
object SumTree {
def main(args: Array[String]): Unit = {
val list: List[Any] = List(List(3, 8), 2, List(5))
println(leafSum(list))
}
def leafSum(list: List[Any]): Int = {
if (list.isEmpty) 0
else
list.foldLeft(0)((tmp, ele) => {
tmp + (ele match {
case a:Int => a
case list: List[_] => leafSum(list)
case _ => 0
})
})
}
}
9.4 匹配对象
/*
对象匹配的本质:
1. 执行到对应的 case 语句后,若 case 后跟的是单个对象,则去调用这个对象的 unapply 方法, 把待匹配值传给这个方法。因此 unapply 方法接收的参数必须是待匹配对象的类型。
2. unapply 方法的返回值必须是 Option(多个元素用元组返回)。如果返回的 Some, 则表示匹配成功, 然后把
Some 中封装的值赋值 case 语句的目标值中;
如果返回的是 None, 表示匹配失败, 继续下一个 case 语句。
注意: 对象() 等价于 对象.apply()
case 对象() => 等价于 对象.unapply
*/
/*
匹配序列时,过程较匹配单个对象略有不同。
1. 执行到对应的 case 语句后,若 case 后跟的是序列对象(可变个元素),则去调用这个对象的 unapplySeq 方法, 把待匹配值传给这个方法。因此 unapplySeq 方法接收的参数必须是待匹配对象的类型。
2. unapplySeq 方法的返回值必须是 Option(序列对象)。如果返回的 Some, 则表示匹配成功。
*/
9.4.1 应用案例
(1)求算术平方根
object Sqrt{
def unapply(arg: Double): Option[Double] = {
if (arg >= 0) Some(math.sqrt(arg))
else None
}
}
object ObjMatch1 {
def main(args: Array[String]): Unit = {
val n = 9.0
n match {
case Sqrt(a) => println(a)
case _ => println("negative input")
}
}
}
(2)获取对象属性
class Person(val name: String, val age: Int)
object Person{
def unapply(arg: Person): Option[(String, Int)] = {
if (arg == null) None
else Some((arg.name, arg.age))
}
}
object ObjMatch2 {
def main(args: Array[String]): Unit = {
val person = new Person("jack", 18)
person match {
case Person(name, age) => println(name + ", " + age)
case _ => println("error")
}
}
}
9.4.2 样例类
样例类集伴生类和伴生对象于一体。
上文中,对象匹配必须要手动在伴生对象中去实现一个def unapply方法。而样例类主要就是为模式匹配而生。样例类就是scala替开发者实现很多方法,而这些方法大部分可以直接使用。
case class User(age: Int, name:String)
1. 写在主构造中的属性默认都是 val, 如果有需要可以改成 var 的。
2. 默认实现了很多方法
apply
unapply
hashCode
equals
toString
3. 使用场景
- 模式匹配
- 替代 java bean
- 作为进程间通信的通讯协议
9.4.2.1 样例类匹配对象
object Match1 {
def main(args: Array[String]): Unit = {
val user: User = User(10, "lisi")
val user1: User = User(10, "lisi")
println(user.equals(user1))
println(user == user1)
println(user eq user1) // 比较是否为同一个对象
user match {
case User(age, name) => println(age + ", " + name)
}
}
}
case class User(age: Int, name: String)
9.4.2.2 匹配序列对象
// 序列对象构造器
class MyList(val names: String*)
object MyList{
// 匹配序列对象,传入参数为序列对象,返回参数为 Option 封装的序列对象
def unapplySeq(s: MyList): Option[List[String]] = {
if(s == null) None
else Some(s.names.toList)
}
// 调用对象构造器生成序列对象
def apply(names: String*) = new MyList(names:_*)
}
object Match3 {
def main(args: Array[String]): Unit = {
val names = MyList("zs", "lisi", "ww", "zs", "zhiling")
// 待匹配对象为序列对象
names match {
case MyList(one, two, rest@_*) =>
println(one)
println(rest)
}
}
}
9.4.2.3 样例类匹配自定义序列对象
// 样例类实现与上文相同的效果,
case class MyCollection(eles: Int*)
object Match4 {
def main(args: Array[String]): Unit = {
val collection: MyCollection = MyCollection(10, 20, 30, 40)
collection match {
case MyCollection(a, b, rest@_*) =>
println(a)
println(rest)
}
}
}
9.4.2.4 模式匹配语义的其他应用
// 1. 接收函数返回值
object Match5 {
def foo = Array(10,20,30,40,50)
def foo1 = (10, 20)
def main(args: Array[String]): Unit = {
val Array(a, b, _*) = foo
println(a + ", " + b)
val (x, _) = foo1
println(x)
}
}
// 2. 遍历集合
object Match6 {
def main(args: Array[String]): Unit = {
val map: Map[String, Int] = Map("a" -> 97, "b" -> 98, "c" -> 99)
for ((x , 98) <- map) {
println(x)
}
}
}
9.4.2.5 偏函数
-
基本介绍
object Match7 { def main(args: Array[String]): Unit = { // 对 list 中的每一个 int 值乘 2,其他值舍弃 val list = List(10, "a", false, 20, 30) // 泛型分别为输入、输出类型 val f: PartialFunction[Any, Int] = new PartialFunction[Any, Int] { // 此函数相当于 filter,过滤符合要求的元素 override def isDefinedAt(x: Any): Boolean = x match { case _: Int => true case _ => false } // 此函数相当于 map,对上一步过滤后的元素进行进一步处理 override def apply(v1: Any): Int = v1 match { case int: Int => int * 2 } } // 支持偏函数只有一个算子 collect // collect 的形参为一个 PartialFunction 的实现类,由于其实现了 (A => B) // 因此也可以当做函数进行传参。 // 在上方创建一个匿名内部类的实例 println(list.collect(f)) // 偏函数可以当做普通函数来使用,函数名() 等于调动了对象的 apply 方法。 // 将 f 直接传入 map 也可以调用其 apply 方法执行 map 逻辑。 println(f(10)) // 偏函数简写形式:一对大括号,通过模式匹配实现 filter 和 map 功能 val list1: List[Int] = list.collect({ case a: Int => a * 2 case b: Boolean => 0 case _ => -1 }) println(list1) } } -
常规应用
object Match9 {
def main(args: Array[String]): Unit = {
// map 匹配及处理
val list = List((1, 2), (10, 20), (100, 200))
val list1 = list.map{
case (age, name) => (age + 100, name)
}
println(list1)
// filter 匹配及处理
val list2 = List((1, (2, 100)), (10, (20, 300)), (100, (200, 400)))
val list3 = list2.filter {
case (a, (b, c)) => c == 300
}
println(list3)
}
}
注意:使用 map + 偏函数 与使用 collect + 偏函数 的区别:使用 map 必须一进一出,没有过滤的环节,如果匹配不上则会抛异常;使用 collect 会调用自带的 filter,如果匹配不上会自行过滤掉。
第十章 异常
java中的都是继承自Exception,分为以下两种:
-
运行时异常
只有在运行的时候才有可能产生,可以处理,也可以不处理。
-
编译时异常(受检异常)
在编译源码的时候产生,必须处理。
在scala中, 所有的异常都可以处理,也可以不处理。
10.1 常规用法
-
处理
-
使用
try catch finally注意:(1)catch 异常的语句使用模式匹配来完成。
(2)try - catch 语句本身同样具有返回值,一般情况下其返回值为 try 语句的最后执行值或 catch 语句的最后执行值。但如果再 finally 语句中添加了显式的 “return” ,那么将返回 “return” 后面的值。
-
抛出异常类型(
java: throws语句; scala:@throws注解 )@throws(classOf[RuntimeException]) @throws(classOf[IllegalArgumentException])注意:抛出异常后最好在调用处进行 try - catch。
-
-
主动抛出
throw new IllegalArgumentException注意:抛出异常后最好在调用处进行 try - catch。
第十一章 泛型
11.1 简介
泛型:类型的参数化
- 泛型类
- 泛型定义在类上, 然后这个泛型在类的内部的任何位置都可以使用。
- 泛型方法(函数)
- 泛型定义在方法上,泛型只能在这个方法中使用。
11.2 泛型的上限界定和下限界定
[T <: Ordered[T]] // 上限
[T >: Pet] // 下限
// 注意:在类型推导的时候,采用的策略和上限是不一样的
11.3 三变
class MyList[T]
class Father
class Son extends Father
11.3.1 不变
MyList[Son] 和 MyList[Father] 没有任何的"父子关系"
错误: val fs: MyList[Father] = new MyList[Son]
// 默认情况下, 所有泛型都是不变的。即子类对象的集合不是父类对象集合的子类。
class MyList[T]
11.3.2 协变
val fs: MyList[Father] = new MyList[Son] // 正确的
// 子类对象的集合是父类对象集合的子类。
class MyList[+T]
11.3.3 逆变
val fs: MyList[Son] = new MyList[Father] // 正确的
// 父类对象的集合是子类对象集合的子类。
class MyList[-T]
11.4 上下文界定
// 自定义伴生类
case class AA(age: Int)
// 自定义伴生对象,声明隐式参数
object AA {
implicit val ord: Ordering[AA] = new Ordering[AA] {
override def compare(x: AA, y: AA): Int = x.age - y.age
}
}
object ContextBound {
def main(args: Array[String]): Unit = {
println(max(10, 20))
println(max("abc", "aaa"))
println(max(AA(10), AA(20)))
}
// 通过上下文界定的方式获得 Ordering 参数值
// 不仅适用于方法定义,也适用于类的定义
def max[T: Ordering](x: T, y: T) = {
// Ordering[T]这个隐式值, 需要从"冥界"召唤
val ord = implicitly[Ordering[T]]
if (ord.gt(x, y)) x
else y
}
// 通过隐式传参的方式获得 Ordering 参数值
def max[T](x: T, y: T)(implicit ord: Ordering[T]) = {
if (ord.gt(x, y)) x
else y
}
}
[T:Ordering]
这就是泛型上下文界定。
表示: 一定有一个隐式值 Ordering[T] 类型的隐式值
上下文泛型的本质其实是对 隐式参数和隐式值 的封装。
11.5 视图界定
视图界定是对象 隐式转换函数 的封装。
case class CC(age: Int)
object ViewBound {
// 隐式函数定义(将没有指定功能的自定义类转换为有指定功能的自定义类)
implicit def f(cc: CC): Ordered[CC] = new Ordered[CC]{
override def compare(that: CC): Int = cc.age - that.age
}
def main(args: Array[String]): Unit = {
println(max(1, 10)) // Int => Ordered[Int] 内部已经定义好了
println(max("aa", "bbb")) // String => Ordered[String] 内部已经定义好了
println(max(CC(20), CC(15)))
}
// 表示一定存在一个隐式转换函数: T => Ordered[T]
// 不仅适用于方法定义,也适用于类的定义
def max[T <% Ordered[T]](x: T, y: T) :T = {
if(x > y) x
else y
}
// 高阶函数隐式传参(相当于隐式参数)
def max[T](x: T, y: T)(implicit f: T => Ordered[T]) :T = {
if(x > y) x
else y
}
}
第十二章 附录
12.1 scala 中下划线的使用
/*
参考资料:
https://stackoverflow.com/questions/8000903/what-are-all-the-uses-of-an-underscore-in-scala
1. 导包, 通配符 _
import java.util.Math._
2. 屏蔽类
import java.util.{HashMap => _, _}
3. 给可变参数传值的时候, 展开
foo(arr:_*)
4. 元组元素访问
t._1
5. 函数参数的占位符
reduce(_ + _)
6. 方法转函数
val f = foo _
7. 给属性设置默认值
class A{
var a: Int = _ // 给a赋值默认的0
}
8. 模式匹配的通配符
case _ => // 匹配所有
9. 模式匹配集合
Array(a, b, rest@_*)
10. 部分应用函数
math.pow(_, 2)
11. 在定义标识符的时候, 把字符和运算符隔开
val a_+ = 10
a+ // 错误
12. List[_]
泛型通配符
13. 自身类型
_: Exception =>
*/
12.2 命令行窗口运行 scala 程序
scalac: 编译 scala 源码
scala: 运行字节码文件
scala 源码.scala
当脚本来运行(内部会先编译,再运行)
12.3 其他补充点
/*
1. 中置运算符
1 + 2
2. 一元运算符
后置
1 toString
前置
+5
-5
!false 取反
~2 按位取反
3. apply方法
任何对象都可以 调用
对象(...) // 对象.apply(...)
伴生对象
普通的对象
函数对象
4. update方法
user(0) = 100 // user.update(0, 100)
*/
-
自定义前置一元运算符 “ ! ”
object Extra2 { def main(args: Array[String]): Unit = { println(!2) } implicit class RichInt(n: Int) { // 后置 // def ! = 10 def unary_! : Int = 10 - n } } -
使用 update 方法操作对象中的集合
object Extra2 { def main(args: Array[String]): Unit = { val user = new User user(0) = 100 // 等价于 user.update(0, 100) user(1) = 200 // 等价于 user.update(1, 200) println(user(0)) println(user(1)) } } class User { val buffer = new Array[Int](10) def apply(index: Int) = buffer(index) def update(index: Int, value: Int) = { buffer(index) = value } } -
面向对象和函数式编程
// 面向对象编程和函数式编程本身就是一对矛盾,在实际编程中有在两者之间进行折中。 纯函数: 1. 没有副作用 - 向控制台打印东西 - 向文件写入数据 - 更改了外部的变量 - 向其他存储系统写入数据 2. 引用透明 这个函数执行的结果, 只和参数有关, 不依赖于其他的任何值! 好处: 1. 不用考虑线程安全问题 2. 可以通过缓存技术, 来提升计算的效率 过程: 没有返回值, 只有符副作用的函数, 就叫过程